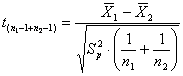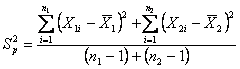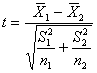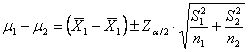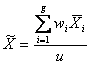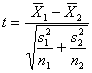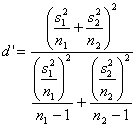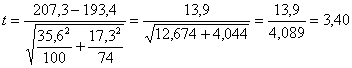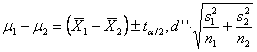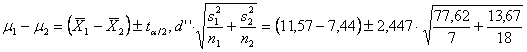|
INFERENZA SU UNA O DUE MEDIE CON IL TEST t DI STUDENT
6.15. IL CONFRONTO TRA DUE MEDIE CON VARIANZE DIFFERENTI O PROBLEMA DI BEHRENS-FISHER; LA STATISTICA DI WELCH E IL METODO DI SATTERTHWAITE. Nei paragrafi precedenti, è stato presentato il test t di Student per due campioni indipendenti (indicati nelle formule con 1 e 2). Esso utilizza la formula
dove
- la varianza comune o pooled è il rapporto tra la somma delle due devianze e dei due gdl,
- i gradi di
libertà sono
Il concetto che sta alla base di tale procedura è che,
- se le due
varianze reali sono uguali (
- le differenze
riscontrate tra le due misure campionarie
Di conseguenza, la
stima più corretta della varianza reale
- è data dalla media
ponderata delle due misure campionarie (
- assegnando peso
proporzionalmente maggiore a quella che è stata calcolata su un campione con un
numero maggiore di osservazioni (
Se il test di
omoscedasticità rifiuta l’ipotesi nulla (cioè si accetta l’ipotesi H1:
Le alternative classiche, per effettuare ugualmente il confronto tra le due medie con varianze differenti, sono: - ricorrere alla trasformazione dei dati, ma se la differenza è grande spesso le due varianze restano diverse; - utilizzare un metodo non parametrico.
Come sottolineano anche Peter Armitage e Geoffry Berry nel loro testo del 1996 (Statistica Medica: metodi statistici per la ricerca in medicina, McGraw-Hill Libri Italia, Milano, 619 pp.; traduzione italiana di Statistical Methods in Medical Research, 1994, Blackwell Scientific Publication Limited, Oxford) molti programmi informatici, - che trascurano i test non parametrici e le trasformazioni, - indirizzano verso l’opzione di un test simile a quello classico di Student, - ma nel quale la varianza comune o pooled è determinata dalla semplice media aritmetica delle due varianze campionarie - e nel quale i valori critici hanno una distribuzione differente da quella classica del t di Student;
- se invece si
utilizza la tabella dei valori critici del t di Student, i gradi di libertà
devono essere calcolati in modo differente e essi risultano tanto minori di
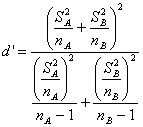
In un articolo del 1992 Barry K. Moser e Gary R. Stevens (Homogeneity of Variance in the Two-Sample Means Test, pubblicato su The American Statistician, Vol. 46, No. 1, pp.19 – 21) nel bollettino della American Statistical Association lamentano che - packages statistici a grande diffusione(e cita SAS, BMDP, SPSS) nel confronto tra due medie abbiano incorporato in modo preliminare l’analisi della varianza tra le due serie di dati - e sulla base di questo risultato indirizzino automaticamente verso il test t di Student classico oppure verso il test SWS (Smith/Welch/Satterthwaite), quando in realtà esisterebbero altre alternative.
Tale test di
significatività, da applicare quando i due campioni indipendenti sono estratti
entrambi da due popolazioni normali (
- la prima con
- la seconda con
per l’ipotesi nulla sulle due medie H0: m1 = m2 è
In essa è modificata la stima dell’errore standard della differenza tra le due medie. Tale test è stato chiamato t approssimato di Welch (Welch's approximate t). Secondo alcuni autori, utilizzare il simbolo t sarebbe da evitare, in quanto induce in errore l’utente di statistica non correttamente informato. Egli potrebbe pensare che si tratti del t di Student, mentre questa distribuzione è differente e ha valori sistematicamente maggiori per gli stessi gradi di libertà. Tuttavia, come è spiegato nelle pagine successive, tale identificazione è approssimativamente corretta, quando si utilizza il metodo di Satterhwaite, che utilizza appunto la distribuzione t di Student, ma con un numero minore di gdl.
Per campioni
grandi le differenze tra gdl diversi diventano minime e si assume che
questa L’intervallo di confidenza è
Resta il problema pratico si decidere quando il campione è abbastanza grande, per questa distribuzione
Ma, per campioni piccoli, la distribuzione di questa t con varianze diseguali è molto più complessa di quella della t di Student. Soprattutto è discussa e vede pochi statistici concordi sulla correttezza dei valori critici, stimati con i vari metodi proposti. Molti testi importanti di statistica applicata non riportano questi metodi, ritenendoli non corretti o almeno non altrettanto accettabili del t di Student. Per una visione più completa anche se critica, è utile ricordare che tra gli autori che hanno affrontato questo problema, i quattro maggiormente citati cono Welch, Smith, Behrens e Satterhwaite.
B. L. Welch nel 1937 con l’articolo The Significance of the Difference Between Two Means When the Population Variances are Unequal (pubblicato su Biometrika, Vol. 29, pp. 350-362) propone una soluzione al problema posto da H. Smith nel 1936 con l’articolo The Problem of Comparing the Results of Two Experiments With Unequals Errors (su Journal of the Council for Scientific and Industrial Research Vol. 9, pp. 211 – 212).
La statistica di Welch (Welch’s statistic), nella sua forma estesa, è un metodo per utilizzare l’analisi della varianza a un criterio, allo scopo di verificare se g medie sono uguali, quando le varianze sono differenti. La statistica di Welch è definita come
dove
-
-
-
-
-
Quando tutte le medie della popolazione sono uguali, - anche se le varianze sono differenti,
-
- con gradi di
libertà
- dove
Più recentemente, per il caso di due campioni un’altra proposta è dovuta a J. M. Davenport e J. T. Webster con l’articolo del 1975 The Behrens–Fisher problem, an old solution revised (pubblicato su Metrika, Vol 22, pp.47-54).
W. B. Behrens già nel 1929 ha proposto una soluzione per il caso di due campioni in un articolo in tedesco Ein Beitrag zur Fehlerberechnung bei weinige Beobachtungen (pubblicato sulla rivista Landwirtsch Jahrbucher Vol. 68, pp. 807-837). Trascurato per lungo tempo, questo metodo ha avuto il grande merito di essere stato presentato da R. A. Fisher e F. Yates nel loro volume di tabelle del 1963 (Statistical Tables for Biological, Agricultural and Medical Research, 6th ed. Oliver and Boyd, Edinburgh). E’ ora ricordato come il metodo di Behrens-Fisher;
F. E. Satterthwaite nel 1946 con l’articolo An Approximate Distribution of Estimates of Variance Components (su Biometrics Bulletin Vol. 2., pp.110 – 114) per i valori critici ha proposto di utilizzare quelli del test t di Student, la cui tabella è facile da reperire su tutti i testi. Ma il metodo della t con varianze ineguali ne differisce per la stima
dei gradi di
libertà
Questo calcolo non fornisce valori interi, per cui si deve
scegliere il valore arrotondato in difetto ( Questo numero di gdl risulta sempre minore di quelli classici per il t di Student con due campioni indipendenti
e in modo tanto più marcato quanto maggiore è la differenza tra le due varianze. Ne deriva che il test risulta più prudenziale, cioè è più difficile rifiutare l’ipotesi nulla, che è l’errore di I tipo che varianze differenti tendono ad accrescere.
Il metodo di Welch, applicato a due campioni, presentava il grave inconveniente che alcuni suoi valori critici risultavano minori di quelli della distribuzione t di Student, per gdl equivalenti. E’ sempre stata ritenuta una soluzione non soddisfacente, in quanto è evidente che in essa i fattori di incertezza sono maggiori, rispetto al metodo tradizionale. La stima dei gdl di Satterthwaite risolve questo problema.
Riassumendo i concetti illustrati, - il test t per due campioni indipendenti con varianza ineguale - secondo il metodo di Satterthwaite (two-sample t test for Independent Samples with Unequal Variances, Sattertwaite’e Method) calcola il valore del t con
i cui gradi di
libertà approssimati
- e alla fine il
risultato di
Sulla tabella
del t di Student si trova il valore critico per questi gdl, che sono
inferiori a quelli classici
Ovviamente diventa più difficile rifiutare l’ipotesi nulla, in quanto per un numero minore di gradi di libertà il valore di t è maggiore. Il test, come quello di Student, può essere sia unilaterale sia bilaterale.
ESEMPIO 1 (TEST UNILATERALE). Tratto con modifiche dal testo di Bernard Rosner del 2000 Fundamentals of Biostatistics (5th ed., Duxbury, Thomson Learning, Australia, XIX + 792 p.). Si vuole verificare se bambini (campione 1), con padre che presenta problemi cardiaci, hanno una quantità di colesterolo maggiore di coetanei (campione 2) con padre senza problemi cardiaci. I dati sono:
- campione 1:
- campione 2:
Risposta. E’ un test unilaterale per la significatività della differenza tra due campioni indipendenti, in cui la varianza è differente. Il valore del t risulta
e i suoi gradi di libertà approssimati
sono
Osservare che nel test t di Student i gdl sarebbero stati 172. Nella tabella dei valori critici, con gdl = 150 nella distribuzione unilaterale, il valore critico risulta t = 2,60. Una stima più precisa della probabilità per un test unilaterale, fornita dai computer, è P = 0.00045. In conclusione si rifiuta l’ipotesi nulla e si afferma che, con probabilità di errare P = 0.00045, la quantità di colesterolo presente in bambini con padre che hanno avuto malattie cardiache è maggiore di quella di bambini con padre senza malattie cardiache.
Per l’intervallo di confidenza o fiduciale della differenza tra due medie (m1 - m2) con il t di Satterthwaite si utilizza
- dopo aver
rifiutato l’ipotesi nulla sulla omogeneità delle due varianze (H1:
- e aver calcolato
i gradi di libertà
ESEMPIO 2 (INTERVALLO DI CONFIDENZA) Valutare la differenza reale alla probabilità a = 0.05 tra le medie di due campioni indipendenti, con le seguenti statistiche
- campione 1:
- campione 2:
Risposta. Le varianze dei due campioni risultano significativamente differenti, poiché
al valore
Il valore
dopo aver
calcolato Nella tabella dei valori critici del t di Student bilaterale, per gdl = 6 e a = 0.05 è riportato t = 2,447 Di conseguenza, l’intervallo di confidenza della differenza tra le due medie alla probabilità a = 0.05 risulta
e ha - come limite inferiore li = 4,13 – 8,42 = - 4,29 - come limite superiore ls = 4,13 + 8,42 = 12,55 Con il t di Student i gradi di libertà sarebbero stato 23 e il valore critico 2,069.
Se e quando usare questi metodi è un dibattito che non trova soluzioni condivise tra gli statistici. Per valutarne la potenza, si impongono due confronti: - tra il test t di Student e questi test t; - tra questi test t e il test non parametrico equivalente più diffuso, il test U o dell’ordine robusto dei ranghi di Mann-Whitney. Rispetto al test t di Student questi metodi sono preferibili, però richiedendo sempre in modo tassativo che le distribuzioni campionarie a confronto siano estratte da due popolazioni distribuite in modo normale, quando - le
varianze sono molto differenti
Altrimenti, se le varianze sono uguali, è preferibile il metodo di Student, in quanto più potente.
Per quanto riguarda il confronto con il test non parametrico, attualmente la preferenza di molti autori è per il test non parametrico, soprattutto se la deviazione dalla normalità è accentuata e/o le varianze sono molto differenti. Con pochi dati, non è mai dimostrabile che le due distribuzioni siano entrambe normali. Zar Jerrold H. nel suo testo del 1999 (Biostatistical Analysis, fourth ed., Prentice Hall, Englewood Cliffs, New Jersey, USA, pp.663 + 203app.) afferma di preferire il test non parametrico e scrive : If there are severe deviations from the normality and/or equality-of variance assumptions, the non parametric test could be employed, as it is not adversely affected by violations of these assumptions, and some researchers would prefer that procedure to the modified test above.
Moser e Stevens (nell’articolo già riportato) contestano la procedura dei pacchetti informatici citati, che obbliga a effettuare l’analisi della varianza preliminarmente e di fondare la scelta tra le due tipologie di test t sulla base di questo risultato. Essi affermano che tale procedura non è appropriata: We now address the question: Is the current pratice of preliminary variance test appropriate? The answer is no. La scelta del tipo di test dovrebbe essere fondata sul rapporto reale tra le due varianze, che nella pratica solo raramente è conosciuto. L’alternativa più sicura, che a un giovane ricercatore offre l’ulteriore vantaggio di essere meno contestata dai referee, è la scelta del test non parametrico. Come inoltre sarà presentato nei casi specifici, i test non parametrici fondati sui ranghi o sulle precedenze perdono poco in potenza, meno del 5%, quando la distribuzione è esattamente normale. Soprattutto in condizioni reali, che spesso si allontanano da quelli del modello statistico, i test non parametrici sono tanto più potenti di quelli parametrici quanto maggiore è la non normalità e l’allontanamento dalle condizioni di omogeneità della varianza. Secondo alcuni è la storia stessa dei pacchetti informatici che può spiegare questa scelta obbligata che essi impongono. I test t per varianze ineguali furono inseriti quando i test non parametrici erano ancora poco diffusi, conosciuti solamente da pochi esperti del settore e non condivisi da tutti. Questi test t, come quello di Welch o meglio di Behrens-Fisher in quanto relativo a due campioni, rappresentavano l’unica alternativa praticabile al t di Student, quando era evidente che le varianze erano differenti. A motivo del comportamento conservativo che tutti i pacchetti statistici devono avere, quello di introdurre le novità ma senza eliminare test già inseriti e utilizzati, questi metodi sono rimasti anche quando da tempo sono proposte alternative, che spesso sono più potenti e possono essere utilizzate in condizioni molto più generali. Resta il fatto che questi metodi per varianze ineguali, soprattutto con il calcolo dei gradi di libertà del metodo di Satterthwaite, sono accettati e proposti dai referee, anche sulla base della semplice constatazione che sono inseriti in vari pacchetti statistici a grande diffusione internazionale.
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |