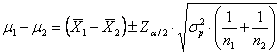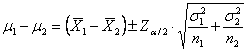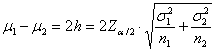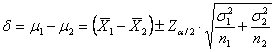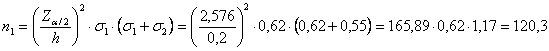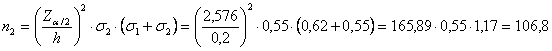VERIFICA DELLE IPOTESITEST PER UN CAMPIONE SULLA TENDENZA CENTRALE CON VARIANZA NOTAE TEST SULLA VARIANZA CON INTERVALLI DI CONFIDENZA
4.12. STIMA DELLA DIFFERENZA TRA DUE MEDIE CON UN ERRORE O UN INTERVALLO DI CONFIDENZA PREFISSATI, NEL CASO DI VARIANZA NOTA
In varie condizioni sperimentali, al ricercatore è richiesto non di effettuare un test di confronto sulla significatività della differenza tra le due medie come nei paragrafi precedenti, ma solamente - di calcolare
la differenza reale d tra le due medie vere - con la precisione minima desiderata o l’errore massimo prestabilito.
Sebbene apparentemente simili ai test precedenti sulla significatività della differenza tra due medie, queste stime sulla precisione della differenza tra due medie sono in realtà nettamente differenti, poiché in questo caso - nella stima
di - non è
implicato il rischio
Il problema è risolvibile partendo dai concetti sull’intervallo di confidenza della differenza
Sempre nelle condizioni di validità illustrate per la significatività della differenza tra le medie di due campioni indipendenti, che si riferiscono soprattutto alla normalità delle due distribuzioni, - i limiti - alla probabilità a predeterminata sono calcolati con due formule differenti, (1) se le varianze sono uguali oppure (2) differenti.
1 – Quando le varianze
sono uguali ( sono
2 – Quando le varianze
diverse ( sono
Con questa ultima
formula, la lunghezza dell’intervallo intorno alla differenza tra le due medie
( - è ricavata da
Da essa si deduce
che, affinché la differenza - la dimensione del campione 1 deve essere almeno
- la dimensione del campione 2 deve essere almeno
ESEMPIO 1 (CALCOLO DELL’INTERVALLO). Una rapida analisi preliminare di pochi campioni sulla quantità di principio attivo immesso nel farmaco da una ditta concorrente in due tempi differenti (indicati rispettivamente con 1 e 2) ha dato i seguenti risultati:
Quale è la
differenza (
Risposta. Assumendo
le due deviazioni standard campionarie
- per la
probabilità dalla relazione
si ricava che alla
probabilità - il limite inferiore L1 = -0,038 - il limite inferiore L2 = +1,974
ESEMPIO 2 (CALCOLO
DI Per ottenere una
misura della differenza tra le due medie che si discosti da quella reale d di una quantità
Risposta. Assumendo
le due deviazioni standard campionarie - - - Z = 2,576 per
la probabilità
1 - la dimensione del campione 1 deve essere
almeno uguale
o superiore a 2 - la dimensione del campione 2 deve essere
almeno uguale o
superiore a
Nella presentazione
di questi metodi, si è assunto che sia nota la varianza Questa sostituzione
del valore campionario - non è più
possibile utilizzare la distribuzione normale ridotta - ma occorre la distribuzione
Il calcolo di
Il calcolo di Ma questo metodo
con
Nella pratica
sperimentale, per queste analisi un campione è ritento grande quando
| |||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |