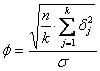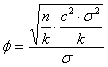|
IL DISEGNO SPERIMENTALE: CAMPIONAMENTO, PROGRAMMAZIONE DELL’ESPERIMENTO E POTENZA
23.7. IL DISEGNO SPERIMENTALE TOTALMENTE RANDOMIZZATO: VANTAGGI, LIMITI E POTENZA.
Nella
programmazione di un esperimento a più fattori, per il quale si è
stabilito che i dati saranno analizzati statisticamente con l’ANOVA a effetti
fissi, si pone spesso il problema di avere una indicazione preliminare,
scientificamente accettabile, del numero - le replicazioni devono essere effettuate contemporaneamente - e il loro numero è indipendente dai risultati dell’esperimento.
Soprattutto per
calcoli manuali che sarebbero lunghi e complessi, il metodo abbreviato più
diffuso è quello proposto da E. S. Pearson (figlio di Karl Pearson) e H.
O. Hartley nel 1951 nell’articolo già ampiamente presentato nei capitoli
dedicati all’analisi della varianza. Anche se ora i calcoli vengono effettuati
con programmi informatici, è ugualmente molto importante comprenderne la logica
e sapere quali sono i parametri fondamentali che determinano queste stime,
dette della potenza a priori ( Gli esempi discussi in questo capitolo seguono le indicazioni fornite da Nicola Montanaro, nel capitolo Lezione 9: il disegno sperimentale del testo pubblicato nel 1977 Biometria, Principi e Metodi, per studenti e ricercatori biologi (Piccin Editore, Padova, XVI + 552 p.), al quale si rimanda per ulteriori approfondimenti.
L’uso delle famiglie di curve per calcolare la potenza (1-b) del test F proposte da Pearson e Hartley, per ricordare i concetti fondamentali, richiede la conoscenza di quattro parametri: 1 - a = il livello di significatività prescelto per il test che sarà applicato, 2 -
3 -
4 - Inoltre l’indice
Il disegno
completamente randomizzato è l’esperimento più semplice. Ma è conveniente
solo quando il materiale utilizzato è altamente omogeneo. Ad esempio, in
un esperimento di laboratorio per valutare l’effetto di - le differenze tra le medie siano imputabili solamente ai differenti effetti dei farmaci, - alla fine dell’esperimento la varianza d’errore sarà minima.
I vantaggi più evidenti di questo disegno sperimentale sono - la facilità dell’esecuzione, - la semplicità dell’analisi statistica, - una varianza d’errore con il numero massimo di gradi di libertà, - il fatto che gruppi non bilanciati, fenomeno frequente quando l’osservazione si prolunga nel tempo, non rendono l’analisi statistica più complessa. Gli svantaggi principali sono che - molto difficilmente in natura, ma spesso anche in laboratorio, si dispone di un materiale così omogeneo; - è ugualmente interessante valutare se, per la variabile analizzata, esistono differenze significative anche entro altri fattori, quali il ceppo, l’età, il peso, il sesso e in generale tra i livelli di tutte le variabili ritenute influenti, anche se ovvie.
Per presentare con un esempio, applicato al disegno completamente randomizzato, i concetti e le formule per calcolare - sia la potenza (1-b) - sia la dimensione
( si supponga di avere
a disposizione 20 cavie per valutare l’effetto di Di conseguenza, per
ognuno dei Il valore del
parametro
In essa, oltre ai simboli già spiegati, - s = deviazione standard della popolazione - dj = mj - m. Per ognuno dei
Nel calcolo di Il parametro Il valore del
parametro Le modalità per effettuare tale operazione sono diverse. Limitiamo la presentazione ai due metodi più semplici e utili
1) Un primo
metodo è assumere che l’ipotesi nulla H0 sia falsa, in
quanto tutte le - che differisce
dalle altre di una quantità Ne deriva che,
rispetto alla media generale - differiscono
tutte di una quantità - mentre la media Si può quindi
ricavare la relazione e da essa per giungere alla
relazione In conclusione si
ha Nella formula per la stima del parametro f, per la relazione
si può eliminare la variabile d e utilizzare la formula semplificata
e infine
semplificare anche
In conclusione non serve più conoscere più né d né s, ma avere solamente una stima del rapporto c.
2) Il secondo
metodo porta a una formula ancora più semplice. Assumendo, sempre con H0
falsa, che esista una differenza tra tutte le medie e la differenza
massima tra la media vera minore e la media vera maggiore sia uguale a
La formula semplificata diventa
e infine,
semplificando anche
Anche in questo caso, è sufficiente una stima approssimata del rapporto tra media e varianza, come fornita anche dal coefficiente di variazione o da altri metodi, discussi nei paragrafi precedenti.
ESEMPIO 1 (CALCOLO
DELLA POTENZA). Calcolare la potenza di un’analisi della varianza a un criterio
con
Risposta. Da
si ricava Dalle dimensioni
dell’esperimento che sono state indicate, cioè un’analisi della varianza a un
criterio con
Nella curva di potenza
con - per - il valore - incontra la curva
per Tale risposta significa che con l’esperimento programmato esiste una probabilità piccola, solo del 32%, che il test risulti significativo.
ESEMPIO 2 (CALCOLO
DEL NUMERO Quanti dati
Risposta. Con i parametri
occorre procedere
per tentativi, in quanto Sulla base
dell’esperienza, per aumentare la potenza si deve assumere un valore di Poiché i gruppi
sono
Dalla lettura dello stesso grafico ( - per - il valore - nel punto in cui
incontra la retta di potenza
Si deve quindi fare
un secondo tentativo, in questo caso abbassando il numero Potrebbe essere con questi parametri
il valore Dalla lettura dello stesso grafico ( - per - il valore Per un esperimento
che abbia la potenza (
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |