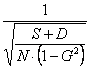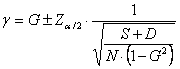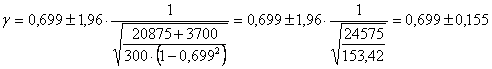|
COEFFICIENTI DI ASSOCIAZIONE, DI COGRADUAZIONE E DELL’ACCORDO RISCHIO RELATIVO E ODDS RATIO
20.7. COGRADUAZIONE PER VARIABILI ORDINALI IN TABELLE r x c: IL g di GOODMAN E KRUSKALL, IL tc.DI KENDALL-STUART, IL dba E dab DI SOMERS.
In una tabella r x c, in cui le due variabili siano di tipo ordinale, l’associazione viene chiamata con il nome specifico di cograduazione. Pure in questo caso, il punto di riferimento sono le due diagonali; ma in modo più complesso, poiché sono prese in considerazione anche le altre caselle. Quando la tabella r x c è impostata con le stesse modalità di quella successiva
- la diagonale dai valori bassi verso quelli alti (a – d) è chiamata diagonale della cograduazione, - la diagonale opposta (c – d) è chiamata diagonale della contro-graduazione.
L’indice di cograduazione più diffuso è il g (presentato anche con il simbolo G) di Goodman e Kruskal presentato nell’articolo del 1954 e nei 3 successivi, già citati. Ha una formula analoga al coefficiente bidirezionale Q di Yule per tabelle 2 x 2 Q = Estesa a una tabella r x c diventa g =
In letteratura il g di Goodman e Kruskal è presentato come una misura di correlazione/associazione, in rapporto al fatto che le variabili siano di tipo ordinale (correlazione) oppure nominale (associazione). Il significato di questo indice, che può essere compreso interpretando la formula per il calcolo, trova la difficoltà maggiore nel capire come sono ottenuti S e D.
Più della definizione - S = somma delle coppie cograduate, partendo dal valore in alto a sinistra: numero totale di coppie di osservazioni in cui si abbiano sia i>i’ e j>j’ oppure entrambi i<i’ e j<j’ - D = somma delle coppie cograduate, partendo dal valore in alto a destra: numero totale di coppie di osservazioni in cui si abbiano sia i>i’ e j<j’ oppure entrambi i<i’ e j>j’ è utile un esempio.
A partire dalla tabella
in cui, A e B in questo caso devono essere due variabili ordinali, ranghizzate (ordinate per rango) in modo crescente, il valore di S è determinato dalla somma di più prodotti Si. Nel caso specifico della tabella i valori Si sono sei, ottenuti come indicato di seguito
1) S1 = 10 (16 + 5 + 13 + 7 + 3 + 4 ) = 10 (48) = 480
2) S2 = 5 (5 + 13 + 3 + 4) = 5 (25) = 125
3) S3 = 18 (13 + 4) = 18 (17) = 306
4) S4 = 8 (7 + 3 + 4) = 8 (14) = 112
5) S5 = 16 (3 + 4) = 16 (7) = 112
6) S6 = 5 (4) = 20
S =
In modo esattamente simmetrico, il valore di D è ottenuto a partire dal valore in alto a destra
1) D1 = 20 (8 + 16 +5 + 11 + 7 + 3) = 20 (50) = 1000 2) D2 = 18 (8 + 16 + 11 + 7) = 18 (42) = 756 3) D3 = 5 (8 + 11) = 5 (19) = 95 4) D4 = 13 (11 + 7 + 3) = 13 (21) = 273 5) D5 = 5 (11 + 7) = 5 (18) = 90 6) D6 = 16 (11) = 176 D = Da S e D si ricava g, indicato spesso con G quando ricavato da dati campionari,
Con l’esempio G = si ricava G = - 0,348. Il segno negativo sta ad indicare che a valori bassi di A sono associati valori alti di B, come evidenzia la tabella dei dati.
Il valore di G dovrebbe essere calcolato su campioni con un numero totale di conteggi (N) grande. E’ quanto avviene normalmente, poiché G è calcolato in tabelle di grandi dimensioni.
Per la significatività di G, appunto perché stimato in grandi campioni, si ricorre alla distribuzione normale Z: - per verificare l’ipotesi nulla H0: g = 0 contro un’ipotesi alternativa che può essere bilaterale H1: g ¹ 0 quando serve un indice nondirezionale (detto anche bidirezionale),
- oppure contro un’ipotesi alternativa unilaterale che può essere H1: g > 0 oppure H1: g < 0 quando si è stimato un indice direzionale, il cui segno (positivo oppure negativo) assume un significato preciso nella disciplina analizzata.
Il test per la significatività di G è
dove - N è il numero totale di osservazioni utilizzate nella tabella e SEG SEG = è l’errore standard di G.
Il valore G calcolato dai dati sperimentali può essere testato non solo rispetto a 0 (H0: g = 0), ma pure rispetto a un valore g atteso, specificato nell’ipotesi nulla (ad esempio, H0: g = 0,7). In questa ultima condizione, il test diventa
L’intervallo di confidenza di g alla probabilità a prefissata è
Quando il valore G è calcolato per due campioni indipendenti (1 e 2) e in condizioni sperimentali del tutto uguali, cioè se - i campioni sono entrambi abbastanza grandi, tanto da poter giustificare per ognuno l’uso della normale, - le due tabelle r x c hanno lo stesso numero di righe e di colonne, - i livelli di ogni variabile, cioè i gruppi ordinali di ogni variabile, sono identici, è possibile confrontare se i due valori G campionari (G1 e G2) sono statisticamente uguali, cioè verificare l’ipotesi nulla H0: g1 = g2 con
in test sia bilaterali che unilaterali.
ESEMPIO (tratto dal testo di David J. Sheskin del 2000, Parametric and nonparametric statistical procedures, 2nd ed. Chapman & Hall/CRC, London, 982 p.). Per valutare se esiste una relazione tra peso alla nascita di un bambino e il suo ordine di nascita, esiste il problema pratico che mentre il primo è misurato su una scala continua, il secondo è una misura di rango con molti valori identici. A tale scopo, i dati di 300 bambini sono stati aggregati in una tabella r x c, di dimensioni 3 x 4,
in cui il peso è stato aggregato in tre gruppi di dimensioni uguali (100), definiti sotto, uguale e sopra la media. Calcolare g e verificare la sua significatività. Inoltre stimare l’intervallo di confidenza di g per a = 0.05
Risposta. Scindendo lo sviluppo dell’esempio nei suoi passaggi logici fondamentali,
1 - è necessario calcolare S e D Il valore di S è dato dalla somma dei seguenti 12 prodotti 1) Cella 11: 70 x (60 + 20 + 10 + 15 + 35 + 40) = 12600 2) Cella 12: 15 x (20 + 10 +35+ 40) = 1765 3) Cella 13: 10 x (10 + 40) = 500 4) Cella 14: 5 x (0) = 0 5) Cella 21: 10 x (15 + 35 + 40) = 900 6) Cella 22: 60 x (35 + 40) = 4500 7) Cella 23: 20 x (40) = 800 8) Cella 24: 10 x (0) = 0 9) Cella 31: 10 x (0) = 0 10) Cella 32: 15 x (0) = 0 11) Cella 33: 35 x (0) = 0 12) Cella 34: 40 x (0) = 0 e risulta S = 20875
Il valore di D, iniziando dall’angolo in alto a destra, è dato dalla somma dei seguenti 12 prodotti 1) Cella 14: 5 x (10 + 60 + 20 + 10 + 15 + 35) = 750 2) Cella 13: 10 x (10 + 60 + 10 + 5) = 950 3) Cella 12: 15 x (10 + 10) = 300 4) Cella 11: 70 x (0) = 0 5) Cella 24: 10 x (10 + 15 + 35) = 600 6) Cella 23: 20 x (10 +15) = 500 7) Cella 22: 60 x (10) = 600 8) Cella 21: 10 x (0) = 0 9) Cella 34: 40 x (0) = 0 10) Cella 33: 35 x (0) = 0 11) Cella 32: 15 x (0) = 0 12) Cella 31: 10 x (0) = 0 e risulta D = 3700
2 – Il valore di G
risulta G = 0,699.
3 - La significatività del valore sperimentale ottenuto G = 0,699, cioè la verifica dell’ipotesi nulla H0: g = 0 contro l’ipotesi alternativa bilaterale oppure unilaterale è
data da Z = 8,847. In una distribuzione normale, Z è altamente significativo sia considerando un test bilaterale che unilaterale.
4 - L’intervallo di confidenza (con Z = 1,96 in quanto richiesto per a = 0.05 in una distribuzione bilaterale)
è uguale a 0,699 ± 0,155 e quindi come - limite inferiore ha l1 = 0,699 – 0,155 = 0,544 - limite superiore ha l2 = 0,699 + 0,155 = 0,854
Il coefficiente tc di Kendall (Kendall’s tau-c), chiamato anche tc di Stuart (Stuart’s tau-c) o tc di Kendall-Stuart (Kendall-Stuart tau-c) è una estensione del tb (specifico per tabelle 2 x 2 e già presentato) a tabelle di dimensioni maggiori, cioè r x c. Il tc di Kendall-Stuart è un coefficiente di cograduazione; è uguale all’eccesso di coppie concordanti su quelle discordanti, con aggiustamento per le dimensioni del campione. Con i simboli usati in precedenza per il g il tc è dato da
in cui - S e D sono uguali alla formula precedente ed ovviamente calcolati nello stesso modo, - Ta = numero totale di coppie di osservazioni in cui i = i’: è la somma dei prodotti di ogni valore per la somma di quelli che sulla stessa riga stanno alla sua destra, a partire dalla prima colonna; - Tb = numero totale di coppie di osservazioni in cui j = j’: è la somma dei prodotti di ogni valore per la somma di quelli che stanno sotto di lui, nella stessa colonna, a partire dalla prima riga.
Dalla stessa tabella utilizzata in precedenza
si ricava che Ta è la somma di 9 valori, dei quali vengono riportati dettagliatamente tutti i calcoli, come spiegazione del metodo: 1) Ta1 = 10 (5 + 18 + 20) = 10 (43) = 430 2) Ta2 = 5 (18 + 20) = 5 (38) = 190 3) Ta3 = 18 (20) = 360 4) Ta4 = 8 (16 + 5 + 13) = 8 (34) = 272 5) Ta5 = 16 (5 + 13) = 16 (18) = 288 6) Ta6 = 5 (13) = 65 7) Ta7 = 11 (7 + 3 + 4) = 11 (14) = 154 8) Ta8 = 7 (3+4) = 7 (7) = 49 9) Ta9 = 3 (4) = 12 Ta =
Tb ( sempre in questa tabella specifica) è la somma di 8 valori: 1) Tb1 = 10 (8 + 11) = 10 (19) = 190 2) Tb2 = 8 (11) = 88 3) Tb3 = 5 (16 + 7) = 5 (23) = 115 4) Tb4 = 16 (7) = 112 5) Tb5 = 18 (5+3) = 18 (8) = 144 6) Tb6 = 5 (3) = 15 7) Tb7 = 20 (13 + 4) = 20 (17) = 340 8) Tb8 = 13 (4) = 52 Tb
=
Applicando la formula di Kendall, si ottiene
un valore di tC = –0,497.
L'elevato numero di calcoli richiesti, anche se semplici, possono determinare errori. E’ quindi utile avvalersi della proposta per la verifica della correttezza di tutti i parametri considerati, attraverso la relazione N2 = 2×(S + D + Ta
+ Tb) + dove - N2 è il quadrato della somma di tutti i dati della tabella, - S, D, Ta e Tb sono i 4 valori utilizzati per la stima dell’indice, -
Con i dati della
tabella utilizzata,
uguale a 1558; di conseguenza, con N = 120; S = 1155; D = 2390; Ta = 1820; Tb = 1056 si dimostra 1202 = 2 (1155 + 2390 + 1820 + 1056) + 1558 = 14400
l’uguaglianza delle due quantità (entrambe danno lo stesso risultato di 14400): è testimoniata la correttezza di tutti i parametri calcolati in precedenza.
Nel 1962 R. H. Somers (con lo stesso articolo citato per il D asimmetrico, A new asymmetric measure of association for ordinal variables, pubblicato su American Sociological Review Vol. 27, n. 6, pp. 700-811) ha proposto anche indici (dba e dab) di cograduazione asimmetrici o unidirezionali per tabelle r x c, da applicare nel caso di variabili ordinali. Come nel titolo dell’articolo, questo indice e i precedenti (gamma, tau-b e tau-c) sono chiamate anche misure di associazione ordinale (ordinal association).
Quando B è la variabile dipendente (e ovviamente A la variabile indipendente), si può stimare dba con
Questa statistica è distribuita in modo approssimativamente normale. La sua varianza è stata stimata da L. A. Goodman e E. H. Kruskal nel 1972 (con l’articolo Measures of association for cross-classification, pubblicata dalla rivista Journal of the American Statistical Association, Vol. 67, pp. 415-421).
Quando A è la variabile dipendente, si stima dab con
con formula simmetrica.
Utilizzando sempre la stessa tabella, con S = 1155; D = 2390; Ta = 1820; Tb = 1056 - dba
risulta uguale a –0,268 e
- dab
risulta uguale a –0,230.
In un confronto tra questi diversi indici, Graham J. G. Upton nel suo volume del 1978 (The analysis of cross-tabuled data, pubblicato da John Wiley & Sons, Chichester, a pag. 38) consiglia, giustificandola come pura scelta personale, di preferire: - per dati nominali, il l di Goodman e Kruskal, - per dati ordinali, il g se le due variabili sono di importanza uguale, - rispettivamente il lb di Goodman e Kruskal o il dba di Somers, se la variabile B dipende dalla variabile A.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||