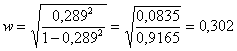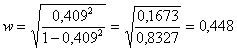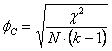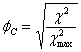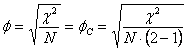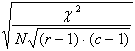|
COEFFICIENTI DI ASSOCIAZIONE, DI COGRADUAZIONE E DELL’ACCORDO RISCHIO RELATIVO E ODDS RATIO
20.4. ASSOCIAZIONE FRA VARIABILI CATEGORIALI O QUALITATIVE: IL C CON LA CORREZIONE DI SAKODA E IL f DI PEARSON, IL fC O V DI CRAMER, IL DT O T di Tschuprow
In una tabella 2 x 2 costruita con le frequenze assolute oppure relative ma sempre conoscendo il numero totale di osservazioni (N), della quale viene riportato lo schema con la consueta simbologia,
la significatività dell’associazione è stimata attraverso il chi quadrato oppure il test G, con tutte le loro varianti di correzioni per la continuità. Nel caso di grandi campioni, è possibile utilizzare la distribuzione normale, eventualmente con la correzione per la continuità. Se il campione è piccolo, per stimare la probabilità si ricorre al metodo esatto di Fisher, ricavato dalla distribuzione ipergeometrica. Semplice nel caso di tabelle 2 x 2, in tabelle r x c la probabilità può essere calcolata solo con l’uso di computer. Attualmente, il metodo è riportato in molti programmi informatici per tabelle di qualsiasi dimensione, appunto perché permette stime esatte di probabilità a differenza del chi-quadrato, del G2 e della distribuzione normale. Questi metodi inferenziali, utili per verificare l’ipotesi nulla H0 che esista indipendenza contro l’ipotesi alternativa H1 che esista associazione tra le due variabili, sono illustrati nel capitolo 3. I metodi inferenziali presentano due limiti gravi: - la significatività del test è strettamente dipendente dal numero (N) di osservazioni; di conseguenza, in campioni grandi possono risultare significative anche associazioni deboli, mentre in campioni piccoli possono risultare non significative anche associazioni forti; - sono test bilaterali, anche se è possibile dimezzare la probabilità, eccetto quelli che utilizzano la Z; essi non indicano la direzione dell’associazione: se positiva oppure negativa.
Dalla tabella precedente, per l’analisi delle relazioni tra le due variabili, possono essere ricavate anche misure su il tipo e l’intensità dell’associazione attraverso l’analisi delle due diagonali, in cui - a-d è la diagonale principale - b-c è la diagonale secondaria. Per convenzione, alla associazione è attribuito - segno positivo, quando le frequenze sono più alte nelle due celle della diagonale principale (a-d); - segno negativo, quando le frequenze sono più alte nelle due celle della diagonale secondaria (b-c).
Definire un’associazione positiva o negativa in questo modo è puramente convenzionale, poiché è sufficiente invertire la posizione delle due righe oppure delle due colonne per ottenere un’associazione di tipo opposto. E’ quindi nella logica della disciplina che si sceglie il segno.
Il concetto di indipendenza o di associazione può essere fatto derivare da quello di equilibrio o squilibrio tra le due modalità di una variabile categoriale. Stimato a partire dai totali marginali, l’equilibrio tra le modalità di una dicotomia è massimo quando ciascuna ha lo stesso numero di dati; in questa situazione si ha anche il massimo di varianza, poiché si ha il massimo di probabilità di errore quando si vuole indovinare se un dato appartiene a una categoria oppure all’altra. Il concetto può essere compreso più facilmente partendo dalla situazione opposta. Se nella zona A tutti i laghi hanno un inquinamento elevato e nella zona B tutti hanno livelli d’inquinamento bassi, come nella tabella seguente,
è facile indovinare, sulla semplice appartenenza alla zona, se il lago ha un livello d’inquinamento alto o basso. Ovviamente, nulla cambierebbe nella capacità predittiva se si avesse una distribuzione opposta, - con i valori massimi collocati sulla diagonale secondaria:
L’associazione emerge con la massima chiarezza, quando le frequenze sono distribuite nelle due celle appartenenti alla stessa diagonale.
Al contrario, quando le due dicotomie sono esattamente equilibrate,
la probabilità di indovinare se il lago abbia un livello d’inquinamento alto o basso, sulla base della zona di appartenenza, è minima: quindi la varianza d’errore è massima.
Come più volte ripetuto, con gruppi categoriali il grado di associazione o di relazione tra due variabili è fornito dal c2 di Pearson. Tuttavia, il valore del c2 calcolato dipende - non solo dallo scostamento delle frequenze osservate da quelle attese (fenomeno che si vuole analizzare), - ma pure dalle dimensioni del campione - e dalle dimensioni della tabella.
Il concetto dell’effetto della dimensione del campione sulla significatività del c2, ovvio per chi abbia un minimo di familiarità con la statistica ma non intuitivo in un corso iniziale, è illustrato con semplicità da David J. Sheskin nel suo testo del 2000 intitolato Parametric and Nonparametric Statistical Procedures (2nd ed. Chapman Hall/CRC, London, 982 p.). Disponendo di una prima distribuzione ipotetica fondata su un campione di 100 osservazioni
si determina
un valore c2 = 9,09. In una seconda distribuzione ipotetica, che ha frequenze relative identiche alla precedente, ma in un campione di dimensioni doppie
si determina
un valore c2 = 18,18. Esattamente il doppio.
Lo stesso concetto, in molti testi, è presentato con una dimostrazione matematica. Il valore dell’associazione tra due variabili qualitative o nominali dipende dalla formula del chi-quadrato: c2 = S Di conseguenza, esso aumenta quando lo scarto tra osservato ed atteso è moltiplicato per una quantità k, anche se le frequenze delle varie classi restano uguali sia in percentuale che nei loro rapporti. Infatti, moltiplicando con un fattore k sia le frequenze osservate che quelle attese
= k
come dimostra l’ultimo passaggio il valore del c2 aumenta di un identico fattore k.
Nell’analisi statistica ne consegue che, per confrontare il livello di associazione misurato in campioni di dimensioni differenti, è necessario ricorrere a indici di associazione. Per comparazioni omogenee e semplici, questi indici devono teoricamente avere due caratteristiche fondamentali: - non risentire delle dimensioni del campione e - avere un campo di variazione tra 0 (indipendenza o assenza di associazione) e 1 (associazione totale). Quelli più frequentemente utilizzati nelle pubblicazioni di statistica applicata sono: - il C di Pearson, eventualmente con l’aggiustamento di Sakoda, - il - il Spesso sono citati anche - il DT o T di Tschuprow, - il l (lambda) di Goodman-Kruskal, (riportato in un paragrafo successivo), - l’UC o U di Theil (riportato sinteticamente in un paragrafo successivo).
A - Il coefficiente di contingenza C (the contingency coefficient C) noto anche come coefficiente di contingenza di Pearson (Pearson’s contingency coefficient) determinato dal rapporto C =
è valido sia per tabelle 2 x 2 che in tabelle r x c. Nelle due tabelle 2 x 2 precedenti, che hanno le stesse frequenze relative ma dimensioni differenti
fornisce un valore identico: C = 0,289. La significatività del valore di C è determinata dal c2. Poiché in tabelle 2 x 2 ha gdl = 1 e il valore critico - per a = 0.005 è c2 = 7,879 - per a = 0.001 è c2 = 10,828 il risultato ottenuto di C = 0,289 - nel campione con 100 osservazioni (c2 = 9,09) è significativo con P < 0.005 - nel campione con 200 osservazioni(c2 = 18,18) è significativo con P < 0.001 E’ utile ricordare che per stimare sia C sia f, il c2 è calcolato senza la correzione di Yates.
Questo confronto dimostra in modo elementare la diversa significatività di campioni che hanno frequenze identiche, quindi lo stesso valore di C, ma dimensioni differenti. Poiché la dimensione N di un campione non può mai essere 0, il valore di C può assumere solo valori 0 £ C < +1
Un limite di questo indice C è che il valore massimo che può essere raggiunto è una funzione del numero di righe e di colonne. Il valore massimo +1 può essere avvicinato solo in tabelle di grandi dimensioni; per questo, vari ricercatori raccomandano di utilizzare tabelle 5 x 5 o di dimensioni maggiori, poiché in tabelle di dimensioni minori il livello di associazione è sottostimato, quando tutte le osservazioni sono collocate sulla diagonale.
Il limite superiore di C (indicato con Cmax) dipende dalle dimensioni della tabella r x c secondo la relazione
dove k è il valore minore tra quello di r e quello di c. Ad esempio, in una tabella di contingenza 2 x 2 come le precedenti, il valore massimo possibile
è Cmax = 0,707. In una tabella 3 x 4, il valore massimo
è Cmax = 0,816. E’ semplice osservare che tende a +1, senza mai raggiungerlo, all’aumentare delle dimensioni della tabella r x c. Il fatto che non possa mai raggiungere +1, anche quando i valori sono collocati totalmente sulla diagonale, indubbiamente rappresenta un limite tecnico del coefficiente; ma ancor più all’interpretazione del risultato. Di conseguenza, può essere utile ricorrere ad un coefficiente di contingenza corretto, chiamato C aggiustato (Cadj) di Sakoda (Sakoda’s adjusted Pearson’s C), mediante la trasformazione
che - riporta a 1 il valore massimo e - permette il confronto tra C stimati su tabelle di dimensioni differenti. Purtroppo quasi nessun programma informatico lo ha inserito nella stima del C di Pearson; ma il passaggio manuale da C a Cadj è semplice Il coefficiente C = 0,289 stimato in precedenza, mediante il rapporto con il valore massimo possibile,
diventa Cadj = 0,409.
Un altro ordine di problemi, collegato al coefficiente di contingenza C di Pearson, è come valutare il contributo delle dimensioni N del campione alla significatività del test c2. Una risposta è stata fornita da J. Cohen nelle due edizioni (1977 e 1988) del suo testo Statistical power analysis for the behavioral sciences con l’indice w (w index)
poiché ogni valore C ingloba anche l’informazione di N.
Fondandosi sulla sua esperienza, quindi con una indicazione puramente arbitraria come sono vari griglie di valutazione in statistica, Cohen ha proposto la seguente scala, per stimare l’effetto delle dimensioni N del campione sulla significatività del c2. Tale effetto è - piccolo (small effect size) se 0.1 < w £ 0.3, - medio (medium effect size) se 0.3 < w £ 0.5 - grande (large effect size) se 0.5 < w
Ad esempio, nelle due tabelle precedenti dove C = 0,289 si ottiene
un valore w = 0,302 uguale per entrambi, seppure con N differente. E’ vicino al limite inferiore di un effetto medio; ma occorre considerare che nel primo caso la significatività è determinata da una probabilità P < 0.005 mentre nel secondo da una probabilità minore, quale P < 0.001. Il valore di C è stato calcolato in un tabella 2 x 2, dove il valore massimo di C non è 1.0 ma 0.707. E’ quindi conveniente in questa stima di w, come altri propongono, utilizzare Cadj = 0,409. Con esso si ottiene
un valore w = 0,448 che, presumibilmente, stima in modo più corretto il contributo di N alla significatività del c2.
B - In tabelle di contingenza 2 x 2 è diffuso il coefficiente f (phi) di Pearson (Pearson’s coefficient of mean-square contingency). Con dati continui dicotomizzati, spesso a questo si preferisce la correlazione tetracorica (tetrachoric correlation), sviluppata da Karl Pearson nel 1901 e basata sull’assunzione che per entrambe le variabili la distribuzione sia continua e normale (vedi l’articolo On the correlation of characters not quantitatively measured, pubblicato su Philosophical Transactions of the Royal Society, Series A, Vol. 195, pp.1-47). Come il precedente indice C, anche il f è utilizzato fin dalle prime applicazioni del test c2 e attribuito a Pearson, per cui non esistono indicazioni bibliografiche sulla sua prima proposta. Trattazioni ampie possono essere trovate nel volume di J. P. Guilford del 1965 Fundamental Statistics in Psycology and Education (4th ed., Mc Graw-Hill Book Company, New York) e in quello di J. L. Fleiss del 1981 Statistical Methods for Rates and Proportions (2nd ed., John Wiley & Sons, New York). In tabelle 2 x 2 può essere calcolato mediante
Eliminando il quadrato al numeratore, con questa formula il coefficiente f offre il vantaggio, rispetto a C, di indicare anche il segno dell’associazione. Dal c2 (calcolato senza la correzione di Yates, come già ricordato) e da N il f può essere ricavato con f = ma solo in valore assoluto. Ad esempio, applicato alla tabella 2 x 2 precedente con N = 200 diventa
oppure
ma perdendo il segno. Come sempre, la significatività dell’indice f è data dal c2.
Concettualmente - il f è la media geometrica delle differenze tra le proporzioni del fattore riportato nelle righe e quello riportato nelle colonne. Ad esempio, riprendendo la tabella
(ma in quella con N = 200 non cambia nulla)
si può osservare che i laghi con un livello d’inquinamento alto (ma considerando quelli ad inquinamento basso si ha lo stesso risultato) - nella zona X hanno proporzione pX = 15 / 50 = 0,30 - nella zona Y hanno proporzione pY = 30 / 50 = 0,60 per cui la loro differenza in valore assoluto è d1 = pX – pY = 0,30 – 0,60 = 0,30
Nello stesso tempo, se prendiamo in considerazione l’altra variabile, vediamo che nella zona X (non cambia nulla se la differenza è calcolata sulla zona Y) - i laghi ad alto inquinamento sono pA = 30 / 90 = 0,3333 - i laghi a basso inquinamento sono pB = 70 / 110 = 0,6364 per cui la loro differenza in valore assoluto è d2 = pA – pB = 0,3333 – 0,6364 = 0,3031.
Il f è
la media geometrica di queste due differenze.
Un altro aspetto importante, altrettanto semplice da osservare direttamente sui valori ottenuti, è che C e f non coincidono; ma tra essi esiste una stretta correlazione quando il f è considerato in valore assoluto. A meno delle approssimazioni introdotte nel calcolo, il valore di f è identico all’indice w. Con tale impostazione, f può servire per valutare l’effetto della dimensione sulla significatività del c2, con gli stessi criteri del w stimato da C. Sempre secondo la griglia di Cohen, tale effetto è - piccolo (small effect size) se 0.1 < f £ 0.3, - medio (medium effect size) se 0.3 < f £ 0.5 - grande (large effect size) se 0.5 < f.
C – In tempi successivi, nel 1946, il coefficiente f è stato esteso da Harald Cramér a tabelle di contingenza di dimensioni r x c (vedi il volume del 1946 intitolato Mathematical Methods of Statistics, Princeton University Press, Princeton, New Jersey, 575 p.). E’ indicato con fC; in altri testi come V e detto V di Cramér (Cramer’s V). E’ l’indice fondato sul c2 che è più diffuso nella statistica applicata per le misure di associazione nominale, a causa della sua buona approssimazione ai limiti di 0 e +1, quando i totali di riga sono uguali a quelli di colonna (r = c) E’ calcolato con
dove - N è il numero totale di osservazioni e - k è il valore minore tra quello di r e quello di c nella tabella di contingenza.
La formula proposta
da Cramér è derivata dall’osservazione che in una tabella di contingenza
il valore massimo che il c2 può raggiungere
(cioè
Di conseguenza, il fC è analogo al Cadj ed è il rapporto tra il c2 calcolato e il suo valore massimo possibile in quella tabella di contingenza campionaria, cioè
In tabelle di contingenza 2 x 2, quindi con k = 2, il f di Pearson e il fC di Cramér coincidono:
Anche il fC può essere convertito nell’indice w attraverso la relazione
In una tabella di contingenza quadrata (r = c), si ottiene fC = 1 quando si ha una correlazione perfetta tra le due variabili, osservabile direttamente sulla tabella dal fatto che tutte le frequenze sono collocate sulla diagonale. Il fC è l’indice di associazione attualmente più utilizzato, a motivo della sua applicabilità a situazioni differenti e la facilità di calcolo. Tuttavia anche esso ha dei limiti: - quando non si ha associazione, non è esattamente 0 ma un valore leggermente maggiore; - quando si ha fC = 1, le due variabili sono perfettamente correlate solamente se la tabella è quadrata; - per stimarne la significatività, la tabella dei dati deve rispettare le condizioni di validità del c2, cioè essere un campione con N abbastanza grande (N > 100 oppure più restrittivamente N > 200) e entro ogni casella solo poche frequenze attese (non oltre il 20%) possono essere inferiori a 5; - non è direttamente paragonabile alle misure di correlazione, quali la r di Pearson, la r di Spearman e la t di Kendall.
D - Analogo come concetti e per lo stesso uso, in alcune pubblicazioni degli anni scorsi è ricorrente anche il coefficiente DT (a volte indicato anche con T) di Tschuprow, statistico di nazionalità russa. In origine, ovviamente il suo cognome è scritto in cirillico; Tschuprow è la translitterazione tedesca del cognome russo; in italiano alcuni autori traducono con Sciuprov. Anche esso è derivato dal c2 mediante la relazione
DT = dove - c e r sono rispettivamente il numero di colonne e di righe - N il numero di osservazioni. Caratteristica di questo indice è che può raggiungere 1 (quindi il valore massimo) qualunque sia il numero di righe e di colonne della tabella di contingenza, ma solo per tabelle quadrate. Per questo motivo, compare su pochi testi e è quasi totalmente ignorato nei programmi informatici. Nella tabella 2 x 2 coincide con il f di Pearson.
Per questi coefficienti non esistono valori critici, in quanto hanno solo significato descrittivo. Sebbene possano essere utilizzate per confrontare l’intensità dell’associazione in tabelle diverse, tutte queste misure basate sul c2 sono di facile interpretazione solo quando il valore è prossimo a 0, cioè esiste indipendenza tra le due variabili e non si ha associazione tra esse.
Esempio (SUL fC DI CRAMER) Nei laghi, la quantità di fosforo è il fattore di norma più importante nel fenomeno della eutrofizzazione. In funzione della sua concentrazione, un lago è classificato in una delle seguenti 5 categorie: ultraoligotrofo, oligotrofo, mesotrofo, eutrofo, ipereutrofo. La stessa definizione può essere data sulla base della quantità di clorofilla o della trasparenza dell'acqua (che dipendono direttamente dalla quantità di biomassa), dalla quantità di azoto, dalla presenza di gruppi caratteristici, dalla frequenza di fioriture algali, dalla distribuzione verticale della biomassa planctonica, dal numero e dal tipo di specie contemporaneamente presenti od assenti.
Per verificare il grado di associazione tra due variabili qualitative, per 66 laghi è stato contato il numero in cui i fattori A e B (che possono essere due specie o due altri qualsiasi fattori qualitativi) che sono presenti(+) od assenti (-) in modo congiunto.
Il lungo elenco è
stato riassunto in una tabella 2 x 2, differente da quella del
Essa evidenzia che in 36 laghi i due fattori sono presenti contemporaneamente, in 5 è presente il fattore B ma assente il fattore A, in 9 è presente il solo fattore A ed assente il B, mentre in 16 laghi sono assenti contemporaneamente sia A che B. Per valutare il
grado di associazione tra le due variabili e stimare la significatività,
dapprima si calcola il valore del
un valore del c2 = 16,898 con 1 df. Successivamente, si deve valutare la significatività dell’associazione. Il valore del E' dimostrata una elevatissima significatività dell'associazione tra queste 2 variabili qualitative: fattore A e fattore B tendono ad essere presenti od assenti in modo congiunto.
Al fine di permettere il confronto tra questo risultato e quello ottenuto con matrici di dimensioni differenti e/o con un numero di osservazioni diverso, si può calcolare - l’indice fC di Cramér
che risulta fC = 0,51. La sua
significatività è quella del
Ma per calcolare l’associazione, il valore dell’indice fC e degli altri deve essere stimato senza il termine di correzione. Di conseguenza, il
valore del sarebbe stato
uguale a 19,212 ed il corrispondente fC di Cramér sarebbe risultato
fC = 0,5395.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||