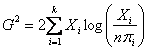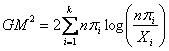|
COEFFICIENTI DI ASSOCIAZIONE, DI COGRADUAZIONE E DELL’ACCORDO RISCHIO RELATIVO E ODDS RATIO
20.2. IL T2 DI FREEMAN-TUKEY E CONFRONTO CON IL c2 E IL G2 NEI TEST PER LA BONTA’ DELL’ADATTAMENTO; CENNI DI ALTRI TEST ANALOGHI.
Il test più diffuso per valutare la bontà dell’adattamento di una distribuzione campionaria a una qualsiasi distribuzione teorica, è il chi-square test
Come illustrato nel paragrafo precedente e con la stessa simbologia, può anche essere scritto
Nel caso di un solo campione, secondo la definizione fornita da H. T. David nel 1968 (alla voce Goodness of fit del volume Int. Encyclopedia of the Social Sciences Vol. 6, pp. 199-206), - il livello di significatività ottenuto con il test statistico per la bontà dell’adattamento (the goodness-of-fit test statistic) è la probabilità che il valore del test ecceda quello calcolato, se il campione osservato fosse stato estratto casualmente da una popolazione che soddisfi le condizioni ipotizzate nel modello.
Con formula differente dalle precedenti, il risultato del chi-square test è ottenuto anche con
dove - N è la somma di tutte le osservazioni del campione.
Benché offra il vantaggio di abbreviare il calcolo del c2 totale, questa formula ha - il grave svantaggio di non calcolare il contributo di ogni cella al valore complessivo. Quindi ha il grave limite di non fornire una informazione, che nella interpretazione del risultato è sempre importante.
Un metodo alternativo per affrontare la stessa serie di problemi e che utilizza la medesima distribuzione c2, è il likelihood ratio
Con una simbologia differente, la formula può essere come
dove - X = - - e dove p =
Il test è descritto in modo dettagliato e confrontato con altri metodi già da S. S. Wilks nel 1938 nell’articolo The large-sample distributionof the likelihood ratio for testing composite hypotheses (su Annals of Mathematical Statistics Vol. 9, pp.: 60-62) Le proprietà sono state descritte da vari autori.
Tra le pubblicazioni importanti possono essere citati - l’articolo di W.
G. Cochran del 1952 The - l’articolo di Vassily Hoeffding del 1965 Asymptotically optimal tests for the multinomial distribution (pubblicato su Annals of Mathematical Statistics Vol. 36, pp. 369 - 401), - quello di R. R. Bahadur del 1967 An optimal property of the likelihood ratio statistic (pubblicato nel volume Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and Probability Vol. 1, pp. 13 – 26).
Un altro metodo che ricorre sempre alla stessa distribuzione c2 è il test c2 di Tukey-Freeman (indicato spesso in letteratura con T2, anche se tale simbolo è usato anche per altri indici)
scritto anche come
Tra gli autori che successivamente ripropongono il T2, sono da ricordare - M. M. Yvonne Bishop (con l’articolo del 1969 Calculating smoothed contingency tables, pubblicato nel volume The National Halothane Study, ed. John P. Bunker, William H. Forrest Jr., Frederick Mosteller and Leroy D. Vandam, National Institutes of Health, Washington D. C., U. S. Government Printing Office, pp. 273 – 286) - M. M. Yvonne Bishop insieme con Stephen Fienberg e Paul W. Holland per il loro volume del 1975 (Discrete Multivariate Analysis, Cambridge, Mass., M.I.T. Press).
Nel 1978 Kinley Larntz ha fornito un confronto tra i tre metodi, per tabelle a più dimensioni (vedi l’articolo Small-sample comparisons of exact levels for chi-squared goodness-of-fit statistics, su Journal of the American Statistical Association Vol. 73, pp. 253-263). In letteratura è possibile trovare anche una formula leggermente differente.
Ad esempio, - nell’articolo di H. B. Lawal e G. J. G. Upton del 1980 An approximation to the distribution of the X2 goodness-of-fit statistic for use with small expectations (pubblicato su Biometrika Vol. 67, pp.: 447 – 453) si parla di - modified Freeman-Tukey statistic
- mentre nell’articolo di S. E. Fienberg del 1979 The use of chi-squared statistic for categorial data problems (su Journal of the Royal Statistical Society, B Vol. 41, pp.: 54 – 64) si trova un’altra definizione della - Freeman-Tukey statistic
La seconda T2
e la F2 differiscono per un termine
Altre proposte sono fondate sul cambiamento del denominatore, al quale viene posta la frequenza osservata in sostituzione di quella attesa. Tra esse, per l’autorevolezza scientifica del proponente la - Neyman-modified statistic
introdotta da J. Neyman
nel 1949 con l’articolo Contribution to the theory of the
- la modified loglikelihood ratio statistic o minimum discriminant information statistic for the external constraints problem
citata da S. Kullback nel 1959 nel volume Information Theory and Statistics (New York, Wiley) e nel 1985 nell’articolo Minimum discriminant information (MDI) estimation (in Encyclopedia of Statistical Sciences, Vol. 5, eds. S: Kotz e N. L. Johnson, New York, Wiley, pp.: 527 – 529)
Per quanto riguarda la loro diffusione nella ricerca applicata, tra questi metodi il test c2 di Pearson è stato quello generalmente utilizzato fino agli anni ’90. Più recentemente, per le sue proprietà additive che saranno illustrate in questo paragrafo e in quelli successivi, ha avuto una grande diffusione il G2 o log likelihodd ratio. Il test T2 di Tukey-Freeman invece, il più noto tra i numerosi metodi alternativi che sono stati proposti in questi decenni, non compare ancora in nessun programma informatico a grande diffusione ed è riportato solo in pochissimi testi per specialisti. Facilmente a motivo del maggior lavoro di calcolo manuale che richiede al ricercatore, della maggiore complessità logica della formula che ne complica la presentazione didattica, dalla mancanza di vantaggi nella interpretazione del risultato. Riveste quindi un interesse pratico molto limitato. E’ stato utilizzato in qualche lavoro scientifico nelle discipline biologiche e ambientali. Pertanto viene presentato in queste dispense.
Benché servano per risolvere lo stesso problema e si applichino agli stessi dati, i tre metodi non forniscono gli stessi risultati. A causa di queste differenti capacità di valutare l’accordo tra la distribuzione osservata e una distribuzione teorica, nella pratica dell’analisi dei dati statistici vari esperti, tra i quali Leo A. Goodman nel 1973 (nell’articolo Guided and Unguided Methods for Selecting Models for a Set of T Multidimensional Contingency Tables, pubblicato su Journal of the American Statistical Association Vol. 68, pp. 165-175), raccomandano di utilizzare più test. Se le probabilità coincidono, le conclusioni risultano rafforzate. Tuttavia non è ancora stata fornita una direttiva condivisa, su come interpretare i risultati, quando le probabilità ottenute con i vari metodi sono molto differenti. Questo problema di sintetizzare risposte divergenti si presenta ora con frequenza maggiore, poiché molti programmi informatici per la stessa analisi riportano non un test solo, ma una intera batteria o serie, lasciando all’utente la scelta tra uno (ma quale?) e la sintesi logica dei vari risultati.
L’illustrazione del metodo T2 e il confronto tra i vari metodi sono ottenuti con la loro applicazione a un esempio.
ESEMPIO. Stimare il valore del “chi-square test” per verificare se le quattro classi fenotipiche, ottenute dalla segregazione di un diibrido, seguono la legge di Mendel (distribuzione attesa 9:3:3:1):
Risposta. 1 - Con la formula
si ottiene
2 - Con la formula
si ottiene
3 - Con la formula
si ottiene
G2 = 2,024 distribuito come un chi-square con 3 gdl.
4 - Con la formula
calcolando separatamente il contributo delle 4 classi
T2 = 2,0529 distribuito come un chi-square con 3 gdl.
Il confronto fra i tre risultati
(considerando che le due formule per il c2 ovviamente forniscono lo stesso valore) riportati in tabella per una comparazione più agevole mostra differenze ridotte, sia in totale che per ogni classe (dove ha significato).
Vari articoli scientifiche, tra le quali quello di Larntz appena citato, provano che le differenze sono di dimensioni maggiori - quando il campione è piccolo e/o - i vari gruppi hanno frequenze attese tra loro molto differenti. In altre termini, le differenze tendono a essere minime quando la distribuzione teorica è rettangolare e il campione è grande.
Per interpretare i risultati, è vantaggioso anche distinguere il contributo fornito da ogni classe o gruppo, come riportati nella tabella precedente. In essa si osserva che - il contributo
maggiore è fornito dallo scarto tra frequenza osservata e frequenza attesa per
la classe - il contributo
minore è quella della classe
Se il problema (come quello dell’esempio) è di genetica, per la esatta comprensione del risultato è sempre importante fornirne una interpretazione da genetista. Ad esempio, se una classe è meno frequente dell’atteso, spiegare perché questi individui, caratterizzati da un fenotipo specifico, sono “selezionati contro” oppure chiarire il vantaggio in “fitness” della classe con un numero di individui osservati maggiore dell’atteso, ecc. … Nell’applicazione della statistica, è sempre fondamentale la spiegazione disciplinare. L’ipotesi nulla da verificare deve nascere entro una teoria o la riprova di un assunto. Per arricchire il dibattito scientifico e fare crescere la conoscenza, il risultato del test deve essere interpretato sulla base dei fattori che hanno fatto nascere l’ipotesi.
Spesso è utile valutare il contributo di ogni gruppo al risultato complessivo. Per questo scopo, il test G2 o log-likelihood ratio si dimostra inadeguato. Tuttavia, anche nei test per la bontà dell’adattamento, quando si dispone di più gruppi è spesso utile scomporre i gradi di libertà in altrettanti confronti ortogonali. E’ l’applicazione in cui il test G2 dimostra vantaggi importanti. Questa logica della scomposizione dei gradi di libertà nei test per la bontà dell’adattamento è del tutto simile a quella già presentata per i confronti a priori nell’analisi della varianza.
Per richiamarne i concetti fondamentali, è utile una loro applicazione all’esempio precedente.
Con 4 gruppi e 3 gdl, è possibile effettuare 3 confronti ortogonali. Tale numero è più ridotto di quello dei confronti possibili; di conseguenza, si pone il problema della loro scelta. Il concetto fondamentale è che tutti i confronti effettuati devono essere impostati in modo tale che il risultato di un confronto qualsiasi non dia informazioni su quello di un altro.
A questo scopo, è sempre richiesta la conoscenza disciplinare delle caratteristiche dei gruppi. Ad esempio, come schematizzato nella tabella,
sono possibili 3 confronti, che tra loro devono essere ortogonali: la somma del prodotto di due coefficienti ortogonali deve dare 0. Ad esempio, il confronto 1° e 3° sono tra loro ortogonali perché (+1/2 x 0) + (1/2 x 0) + (-1/2 x +1) + (-1/2 x –1) = 0 Lo stesso risultato è fornito dalle altre due coppie di confronti, cioè il 1° rispetto al 3°, il 2° rispetto al 3°.
I tre confronti individuati nell’ultima tabella forniscono i seguenti valori del c2 e del G2.
I) Con il primo
test, che ha 1 gdl, è possibile chiedersi se il rapporto tra le classi
contenenti l’allele
Con il c2 si ottiene
Con il G2 si ottiene
II) Con un secondo
test, che ha 1 gdl, è possibile chiedersi se entro il fenotipo
Con il c2 si ottiene
Con il G2 si ottiene
III) Con il terzo
test, che ha sempre 1 gdl, è possibile chiedersi se entro il fenotipo
Con il c2 si ottiene
Con il G2 si ottiene
I risultati dei due metodi, nei tre test di scomposizione dei 3 gdl complessivi, sono tra loro molto vicini:
Ma mentre - la somma dei tre test con 1 gdl del test G2 (2,0240) coincide esattamente con quello ottenuto in precedenza mediante l’analisi simultanea delle 4 quattro classi (2,0240), - la somma dei tre
test La scomposizione dei confronti ortogonali con il test G2 è additiva, come i gdl.; con il test c2 è solo approssimata.
La scomposizione dei 3 gdl avrebbe potuto seguire un percorso differente. Ad esempio, sarebbe stato possibile iniziare da B. In questa condizione, i tre confronti sarebbero stati
Non è corretto effettuarli entrambi, scegliendo a posteriori la serie più significativa. Come illustrato nei paragrafi dedicati ai confronti multipli a posteriori, si altera la probabilità a experiment-wise o family-wise. Compete al biologo scegliere, sulla base del problema che intende verificare. Ovviamente i confronti effettuati e i risultati ottenuti sono differenti.
Non è necessario arrivare sempre alla scomposizione di tutti i gdl. Alcuni confronti, possono avere più di un solo gdl. A ulteriore dimostrazione delle svariate possibilità di scelta dei confronti che è possibile effettuare sulla stessa serie di gruppi campionari, ne è presentata una ancora differente. Ad esempio, fondato
su un problema di genetica quantitativa, con un approccio totalmente diverso si
può partire dalla semplice verifica se il gruppo con i due geni recessivi (
Questo primo confronto ha 1 gdl. Con il c2 si ottiene
Con il G2 si ottiene
Successivamente, è
possibile utilizzare i 2 gdl rimanenti per verificare se i tre gruppi
Con il c2 si ottiene
Con il G2 si ottiene
La somma dei due confronti
dimostra ancora una volta che - i risultati ottenuti con i due metodi sono sempre simili anche se non coincidenti: la differenza maggiore è nel primo confronto, dove le classi sono tra loro fortemente sbilanciate, - la somma dei due G2 (2,0240) coincide esattamente sia con quello ottenuto in precedenza mediante l’analisi simultanea delle 4 quattro classi (2,0240), sia con la scomposizione precedente, - il risultato
della somma dei due test In sostituzione di questo ultimo calcolo con 3 gruppi e quindi 2 gdl, è possibile effettuare 2 confronti ortogonali con 2 classi ognuno; non entrambi.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||