|
LA REGRESSIONE LINEARE SEMPLICE
16.14. ERRORI DELLE VARIABILI E INTERVALLI DI TOLLERANZA
Per analizzare la regressione di Y su X, - non si prende in considerazione alcuna forma di variabilità casuale dei valori di X, ma solamente quella di Y. Questo concetto è applicato correttamente nello studio delle relazioni tra dose e effetto. Come esempi classici sono citati gli esperimenti di tossicologia e di farmacologia, dove - la dose (X) di principio attivo somministrata è misurata in modo preciso, con l’unico errore trascurabile dato dallo strumento, - mentre la risposta (Y) è fisiologica: solamente essa presenta la variabilità individuale.
In altri casi, è evidente che questa concetto non è corretto: - la variabile X non è affetta solamente da errori di misura, ma ha gli stessi errori della variabile Y. Questo argomento è discusso nel capitolo sulla regressione Model II o least-products. Nell’esempio ripetutamente utilizzato nei paragrafi precedenti, la relazione lineare tra peso (Y) e altezza (X), può apparire a chi non ha esperienza statistica che i valori della variabile indipendente X abbiano le stesse variazioni casuali della variabile dipendente Y, in quanto entrambi appaiono affetti sia da errori di misura analoghi sia dalle stesse variazioni individuali. In realtà, nella trattazione classica della regressione lineare, anche in questo esempio gli errori casuali di X non sono presi in considerazione: - viene analizzata solamente la variabilità delle Y, in quanto è la “risposta” o effetto rispetto allo “stimolo” o causa (X).
Per comprendere esattamente questo concetto è utile rifarsi alle analisi di Galton. La variabile X rappresenta l’altezza media dei genitori che, con il loro patrimonio genetico, determinano l’altezza (Y) del figlio, in una trasmissione che risente anche di altri effetti, tra cui quelli ambientali. Recentemente, sono
stati proposti approcci più complessi che intendono valutare il valore vero di
X stimato (
Nello studio della regressione, l’ipotesi di omoscedalità o omoschedasticità (l’ipotesi di indipendenza dell’errore o di omogeneità della varianza) e quella di normalità della loro distribuzione riguardano solo le Y.
Quando le condizioni di validità, che verranno di seguito discusse, non sono rispettate, è possibile ricorrere - a una regressione lineare non parametrica (che sarà presentata in un capitolo successivo), - all'uso di metodi least-products, detti anche regressione model II (presentati in un capitolo successivo), - a una trasformazione dei dati, - a una valutazione e descrizione della regressione mediante i limiti di tolleranza.
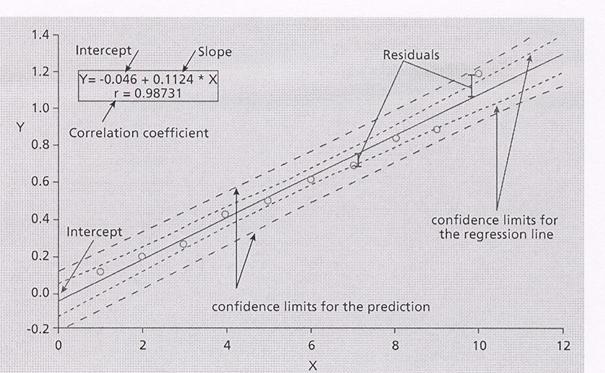
Nella figura, sono rappresentati - i limiti di confidenza della retta di regressione (confidence limits for the regression line) - i limiti di confidenza per la previsione (confidence limits for the prediction) chiamati anche, più rapidamente, intervalli di previsione (prediction intervals).
I limiti di tolleranza (tolerance limits) o intervalli di tolleranza (tolerance intervals) forniscono il campo di variazione entro il quale è contenuta una percentuale stabilita di singole misure della popolazione, alla probabilità prefissata. Poiché anche essi sono calcolati a partire da dati campionari, per definire un intervallo di tolleranza è necessario fornire due misure: - il grado o
livello di confidenza, vale il rischio - la percentuale di misure della popolazione compresa nell’intervallo. Ad esempio, la
probabilità del 95% (
Nel caso di una distribuzione univariata, i limiti dell’intervallo di tolleranza sono dati da
dove - - La loro relazione è
dove - il valore L’intervallo di tolleranza è ricavato con facilità quando di descrivono i dati di un campione. E’ un metodo utile per rappresentare l’evoluzione temporale di un fenomeno (X uguale al tempo) oppure la risposta dose-effetto, quando la regressione non sia ritenuta corretta, poiché nel diagramma di dispersione dei dati si evidenzia almeno una delle caratteristiche seguenti, (considerando la Y): - una distribuzione di valori non normali, non simmetrici rispetto alla tendenza centrale, - una variabilità differente al variare della X, - la presenza di outliers.
L’uso dei limiti di tolleranza permette di individuare l’evoluzione della tendenza centrale, cioè quali valori di Y rientrano nella norma e quali se ne discostano in modo rilevante, sulla base della loro frequenza. La tecnica può essere applicata a qualunque tipo di regressione.
L’intervallo di tolleranza, quando fondato sui centili, - con la mediana (per ogni tempo o dose di X) individua la tendenza centrale, - mentre i quartili, i decili oppure i centili (eventualmente tra loro collegati con segmenti, per meglio evidenziare la striscia entro la quale sono compresi i valori “accettabili”) descrivono la variabilità di una distribuzione di dati, misurati con una scala che sia almeno di tipo ordinale.
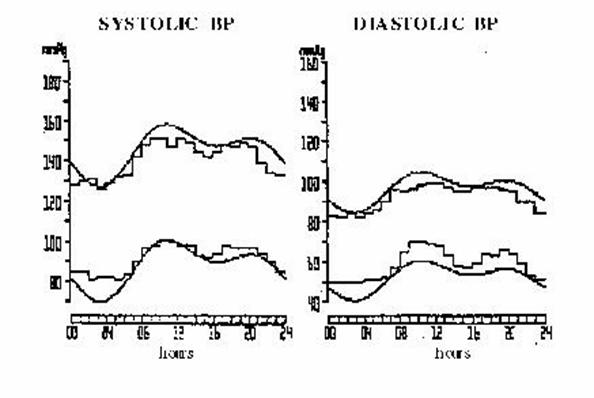
Ad esempio, nelle due figure sono riportati i limiti della pressione sistolica (a sinistra) e di quella diastolica (a destra) di un gruppo di individui, durante le ore del giorno. Per ogni gruppo che sia formato da un numero sufficiente di dati, è semplice individuare la mediana, i quartili e i centili. Di questi ultimi, spesso sono utilizzati quelli che escludono il 20%, il 10% o il 5% dei valori in una o in entrambe le code della distribuzione. La scelta dipende dalla diversa importanza clinica dei livelli di pressione più alti e più bassi. Più in generale, le
quantità dei percentili estremi da evidenziare sono scelte in rapporto ai
fenomeni che si intende analizzare. Unendo con un tratteggio le mediane e gli
stessi centili a ore diverse, si ottiene un intervallo o più intervalli di
tolleranza che sono solamente analoghi agli intervalli di confidenza della
retta. In questo caso, infatti, è evidenziata la dispersione dei valori
individuali, mentre l’intervallo di confidenza fornisce la dispersione dei
valori medi In questo caso, gli intervalli di tolleranza sono rappresentazioni bidimensionali che descrivono graficamente l’evoluzione della tendenza centrale e le caratteristiche fondamentali della dispersione dei dati, per ogni raggruppamento effettuato.
L'intervallo di tolleranza è una tecnica descrittiva, non un test inferenziale. E’ applicata soprattutto per mostrare l’evoluzione geografico-temporale di una variabile. Può essere una serie annuale di valori d’inquinamento, rilevati giornalmente; la relazione dose-risposta, quando la risposta Y individuale non è simmetrica attorno ai valori medi e/o la variabilità non è costante, ma varia in funzione dello stimolo X. Per verificare se questa mediana o linea che unisce i quantili uguali tende a variare in modo significativo, si può ricorrere - ai test non parametrici di tendenza, illustrati in un capitolo successivo.
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |