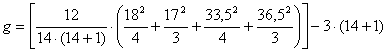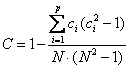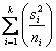|
TEST NON PARAMETRICI PER PIU' CAMPIONI
15.6. TEST PER L’ETEROGENEITA’ DELLA VARIANZA CON K CAMPIONI
Nella ricerca biologica, medica, ecologica ed ambientale, sono frequenti le situazioni in cui l’attenzione del ricercatore è rivolta alla variabilità dei dati, più che alla loro tendenza centrale. E’ il caso di misure d’inquinamento che in zone differenti possono avere una variabilità diversa, pure con una tendenza centrale simile; anche se per l’inquinamento le mediane sono tutte sotto i limiti di legge, dove la varianza risulta maggiore è più urgente intervenire, poiché singole osservazioni possono superarli con frequenza più alta. E’ il caso di farmaci, dove è importante la riposta media allo stimolo di una dose, ma ancor più la variabilità tra individui: un farmaco con una media peggiore può essere preferito, se garantisce una maggiore omogeneità di risposta dei pazienti. Il controllo di qualità di un prodotto industriale è fondato sulle modalità di riduzione della varianza, per garantire che tutte le confezioni siano uguali. Inoltre, come discorso più generale di confronto tra popolazioni, è possibile affermare che k serie di dati campionari appartengono a popolazioni differenti, se hanno varianze statisticamente non uguali. E’ un problema già discusso nel caso di 2 campioni indipendenti, che può essere facilmente esteso a k campioni, nello stesso modo con il quale il test WMW (Wilcoxon-Mann-Whitney) ha la sua generalizzazione nel test KW (Kruskal-Wallis). Nella statistica parametrica è il test di Levene, di cui questo test può essere interpretato come il corrispondente non parametrico. Da una distribuzione di dati classificati in k gruppi, - si calcola la media di ogni gruppo - e entro essi le differenze in valore assoluto di ogni dato dalla sua media; - a questi k gruppi di differenze si applica il test di Kruskal-Wallis sulle mediane; - se il test risulta significativo, vuol dire che le mediane delle differenze sono significative; - in altri termini, le varianze dei k gruppi sono significativamente differenti.
In modo più dettagliato, prendendo come esempio d’applicazione un articolo pubblicato sulla rivista Applied Statistics nel 1989 (di D. V. Hinkley, Modified profile likelihood in trasformed linear models, Vol. 38, pp. 495-506), la procedura presentata da P. Sprent nel volume Applied nonparametric statistical methods, (second Edition, Chapman & Hall, London, 1993, pp. 155-156) prevede che
1 - per la verifica dell’ipotesi nulla H0: s2 A = s2B = … = s2K contro l’ipotesi alternativa H1: le s2 dei gruppi a confronto non sono tutte uguali in un caso con pochi dati (meno di quelli richiesti dal metodo di Moses per 2 campioni indipendenti, già illustrato), situazione non rara nella ricerca ambientale e biologica,
2 - dopo il calcolo
delle medie (
3 - si debbano stimare le deviazioni, in valore assoluto, di ogni dato dalla media del suo gruppo
ottenendo una nuova tabella di scarti assoluti come la seguente
A essi si applica il test di Kruskal-Wallis, per valutare se hanno dimensioni medie (cioè le mediane se si parla dei valori, le medie se si parla dei loro ranghi) differenti.
4 – Di conseguenza, i dati riportati nell’ultima tabella devono essere ulteriormente modificati nei ranghi relativi, considerando tutto il campione e ottenendo
5 - Se l’ipotesi nulla è vera (variabilità uguale in ogni gruppo), i ranghi di ogni gruppo dovrebbero essere distribuiti casualmente e quindi avere medie uguali, sia tra loro, sia alla media generale. Se l’ipotesi nulla è falsa, la media dei ranghi di almeno un gruppo dovrebbe essere significativamente differente da quella dagli altri. E’ la stessa condizione (sulle medie dei ranghi e mediane dei valori) verificata dal test di Kruskal-Wallis (che può essere applicato sui ranghi dell’ultima tabella).
6 - Per giungere alla stima di g con la formula abbreviata
dapprima si calcolano i totali ( Ri ) dei ranghi e il numero di osservazioni (ni) entro ogni gruppo
e con N = 14
si ottiene g = 6,54 .
Il risultato deve essere confrontato con i valori critici del c2. Per k = 4 gruppi, i gdl sono 3; il valore critico alla probabilità a = 0.05 è uguale a 7,815. Non è possibile rifiutare l’ipotesi nulla: i vari gruppi non hanno una variabilità significativamente differente.
Poiché esistono valori identici, è possibile apportare la correzione relativa. Ricorrendo alla formula già illustrata
dove: - p è il numero di raggruppamenti con ranghi ripetuti, - c è il numero di ranghi ripetuti nel raggruppamento i-esimo, - N è il numero totale di osservazioni nei k campioni a confronto.
Ad esempio, con p = 2 e c = 2 si ottiene un termine di correzione C
C = 1-
uguale a 0,9956 che non modifica sostanzialmente il valore di g corretto g corretto = 6,54 / 0,9956 = 6,57 risultando uguale a 6,57 con arrotondamento, rispetto al 6,54 precedente.
Poiché il campione è piccolo ed esistono valori identici, come pubblicato anche da Hinkley, è conveniente usare un’altra correzione che, scritta nei suoi passaggi operativi, è g = dove Sp = con si = år2ik (sommatoria del quadrato dei ranghi dei k gruppi) e ni = numero di dati di un gruppo Sr = åi,kr4ik (sommatoria di tutti i ranghi elevati alla quarta) C = Con i dati dell’esempio, s1 = 72 + 4,52 + 4,52 + 22 = 93,5 s2 = 32 + 62 + 82 = 109,0 s3 = 12,52 + 112 + 12 + 92 = 359,25 s4 = 12,52 + 142 + 102 = 452,25 con s1 + s2 + s3 + s4 = N×(N+1)×(2N+1) / 6 solo quando non esistono valori identici infatti 93,5 + 109,0 + 359 25 + 452,25 = 1014 mentre 14 x 15 x 29 / 6 = 1015
Dai valori s1, s2, s3, s4 si ottiene Sp mediante Sp = (93,52 / 4) + (1092 / 3) + (359,252 / 4) + (452.252 / 3) = 106.587,724che risulta uguale a 106.587,724
mentre Sr è dato dalla somma di tutti i 14 ranghi alla quarta Sr = 74 + 4,54 + 4,54 + 24 + + 12,54 + 144 + 104 = 127.157,25 e risulta uguale a 127.157,25
e C è dato dal quadrato della somma dei k si diviso N C = 10142 / 14 = 73.442, 571 e risulta uguale a 73.442,571.
Da essi si stima il valore corretto di g
g =
che risulta uguale a 8,0217. Il nuovo valore risulta significativo alla probabilità a = 0.05 e rovescia le conclusioni precedenti fondate su altre modalità di correzione; con questo metodo, si evidenzia una differenza significativa nella variabilità dei 4 gruppi di dati.
Come il test di Levene è più potente dei test tradizionali fondati sui rapporti tra le varianze (Hartley e Cochran ai quali può essere aggiunto Bartlett, anche se ha una metodologia differente) questo test risulta più potente di quelli fondati su misure dirette di variabilità. E’ quindi consigliato nei testi più recenti e è stato inserito nei programmi informatici più diffusi.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||