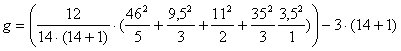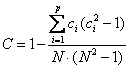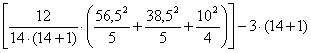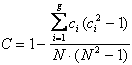|
TEST NON PARAMETRICI PER PIU' CAMPIONI
15.4. Analisi della varianza per ranghi, a un criterio di classificazione: IL Test di Kruskal-Wallis
Quando si utilizzano misure rilevate con una scala continua, seppure ordinale, quindi tutti i dati possono essere disposti in ranghi con un numero nullo o comunque ridottissimo di valori uguali, è utile ricorrere ad un test più potente del test della mediana. La quantità di informazione contenuta in ogni osservazione è superiore a quella utilizzata nel test della mediana, che si limita a classificare i valori in alti e bassi; di conseguenza, diviene più probabile verificare la significatività della differenza nella tendenza centrale, pure disponendo di un numero inferiori di dati. E’ lo stesso concetto espresso nel confronto tra il test dei segni e il test di Wilcoxon-Mann-Whitney, nel caso di due campioni. Il test proposto nel 1952 da W.H. Kruskal e W. A. Wallis, chiamato Kruskal-Wallis One-Way ANOVA by Ranks o più semplicemente the Kruskal-Wallis test, (con l’articolo Use of ranks in one criterion variance analysis pubblicato su Journal of the American Statistical Association vol. 47, pp. 583–621 e con quello del solo Kruskal sempre del 1952 A non parametric test for the several sample problem pubblicato su Annals of Mathematical Statistics vol. 23, pp. 525-540) è l’equivalente non parametrico dell’analisi della varianza ad un criterio di classificazione. E’ uno dei test più potenti per verificare l'ipotesi nulla H0, cioè se k gruppi indipendenti provengano dalla stessa popolazione e/o da popolazioni che abbiano la medesima mediana.
Anche la metodologia del test di Kruskal-Wallis è molto semplice e può essere schematizzata in alcuni passaggi.
1 – Per verificare l’ipotesi nulla che tutti i campioni hanno la stessa mediana H0: meA = meB = meC = meD = meE con ipotesi alternativa che almeno una è differente o H1: non tutte le mediane sono uguali come nell’analisi della varianza ad un criterio di classificazione, i dati dei k gruppi a confronto
possono essere riportati in una tabella. I gruppi a confronto possono avere un diverso numero d’osservazioni.
2 - Tutte le osservazioni dei k gruppi devono essere considerate come una serie unica e convertite in ranghi, mantenendo la stessa forma della tabella;
Se sono presenti misure uguali, a ciascuna di esse deve essere assegnato il loro rango medio.
2 - Tutte le osservazioni dei k gruppi devono essere considerate come una serie unica e convertite in ranghi, mantenendo la stessa forma della tabella;
Alle misure uguali, deve essere assegnato il loro rango medio.
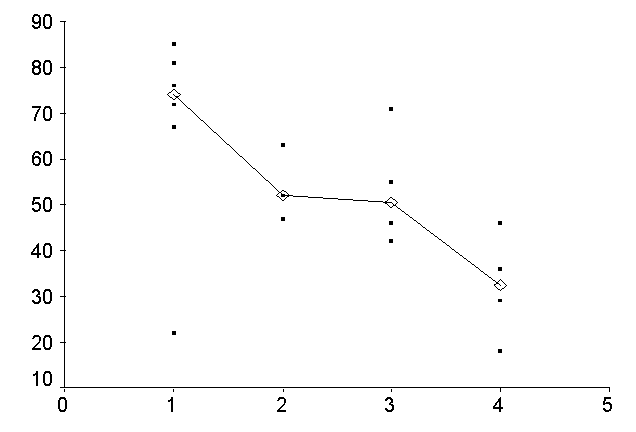
Le misure originali, rappresentate su un diagramma cartesiano, evidenziano la maggiore variabilità dei dati del primo gruppo rispetto agli altri, in particolare di quella del secondo; inoltre questo gruppo ha un numero di dati sensibilmente minore, troppo piccolo per un confronto reale tra le varianze, che abbia una potenza sufficiente da rendere il risultato credibile. Sono caratteristiche che devono indurre all’uso del test non parametrico.
3 – Calcolare,
come riportato nella tabella, -
la
somma dei ranghi di ogni gruppo ( -
il
numero di osservazioni di ogni gruppo ( -
da
cui la media di ogni gruppo ( Con R = 76 + 28 + 34,5 + 14,5 = 153 e N = 6 + 3 + 4 + 4 = 17 la media generale
risulta uguale a 9.
4 - Se i campioni
provengono dalla stessa popolazione o da popolazioni con la stessa tendenza
centrale (H0 vera), queste medie aritmetiche dei ranghi di
ogni gruppo ( Da questo concetto è possibile derivare la formula per il calcolo di un indice (g), che dipende dalle differenze tra le medie dei gruppi e la media generale. (Nella formula sottostante, la differenza tra la media di ogni gruppo e la media generale è nascosta dall’uso della somma totale dei ranghi, che ovviamente dipende da N)
g =
La quantità N (N + 1) / 12è la varianza (riportata al denominatore nelle formule generali), che dipende solo da N, mentre la media
degli
Come nell’analisi della varianza, il parametro g (vari testi lo indicano con KW, iniziali dei due autori) può essere calcolato a partire dalle somme, con una formula abbreviata che offre anche il vantaggio di evitare le approssimazioni dovute alle medie
dove: -
-
-
-
e la sommatoria è estesa a tutti i k gruppi.
Di conseguenza, con una formula che evidenzia in modo più evidente le sue componenti, anche se i calcoli richiedono un tempo maggiore, l’ipotesi di uguaglianza fra mediane è basata sulla funzione
g = dove -
-
Nel caso di campioni piccoli e con valori ripetuti, è conveniente dare la preferenza a questa ultima formula.
Il parametro
g si distribuisce approssimativamente come la distribuzione L'approssimazione alla distribuzione chi quadrato è tanto migliore quanto maggiore è il numero (k) di gruppi e il numero di osservazioni entro ogni gruppo è alto, maggiore di 5. Quando il numero
di gruppi a confronto è ridotto (uguale a 3) ed il numero di
osservazioni entro ogni gruppo è basso (inferiore a 5) la distorsione dalla
distribuzione
Sono tavole limitate a casi molto particolari, in quanto valgono solo per analisi con 3 gruppi e dimensioni non superiori a 5 osservazioni in ogni gruppo. Esse iniziano da dimensioni minime di 2, 1 e 1, nei 3 gruppi. Sono dimensioni nettamente inferiori a quelle richieste per il test F: per campioni molto piccoli, è quindi preferibile ricorrere a questo test non parametrico. Si rifiuta l’ipotesi nulla, alla probabilità a riportata nella tabella, quando il valore g (oppure KW) calcolato è uguale o superiore a quello critico riportato nella tabella. L’ultima riga coincide con i valori critici della distribuzione chi quadrato per gradi di libertà 2.
A differenza dell’analisi della varianza, il test di Kruskal-Wallis può essere utilizzato anche quando un gruppo ha una sola osservazione. Dal testo Non Parametric Statistical Methods di M. Hollander e D. Wolfe (John Wiley & Sons, New York) del 1973 è tratto questo esempio, sulle percentuali di acqua contenuta in cinque sostanze diverse:
Tabella dei valori critici di g (o KW) del test di Kruskal -Wallis, per confronti fra 3 campioni con un numero ridotto di osservazioni( £ 5).
I 3 campioni devono essere ordinati per dimensioni in modo decrescente(l’ultima riga coincide con il c2 per 2 df)
Percentuali di acqua contenuta in 5 campioni
Dopo trasformazione in ranghi ed aver
calcolato sia la somma dei ranghi sia
con N = 14 attraverso
si stima
Non è possibile rifiutare l’ipotesi nulla. Ma, poiché il valore calcolato è vicino a quello critico e corrisponde a una probabilità P leggermente superiore a 0.05, si può concludere che è tendenzialmente significativo. Con un numero leggermente maggiore di dati il test probabilmente sarebbe significativo.
Recentemente è stato evidenziato, come mostra una lettura attenta dei valori critici riportati nella tabella, che il valore di g non è monotono: il suo andamento - è prima crescente e poi decrescente, - è asimmetrico e caratterizzato da numerosi valori modali. Pertanto, sono state evidenziate perplessità sulla sua effettiva capacità di permettere la verifica di ipotesi sull’uguaglianza di mediane; di conseguenza sono state proposte alcune modifiche, che tuttavia sono ancora poco utilizzate.
Il test di Kruskal-Wallis, fondato sui ranghi, è analogo all’analisi della varianza ad un criterio di classificazione, come il test di Wilcoxon-Mann-Whitney, fondato ugualmente sui ranghi, è analogo al test t di Student. Lo stesso confronto vale per la sua efficienza asintotica relativa. L’efficienza asintotica relativa del test KW rispetto al test F è quindi identica a quelle del test WMW rispetto al t: - quando la distribuzione dei dati è Normale ha un valore uguale a 0,95 (3/p), - quando la distribuzione dei dati è Rettangolare ha un valore uguale a 1, - quando la distribuzione dei dati è Esponenziale Doppia ha un valore uguale a 1,50 (3/2).
Esempio
1. L'ozono si forma da Durante una
giornata estiva, in quattro zone di una città (A, B, C, D) si sono rilevate le
concentrazioni di
Esiste una
differenza significativa tra le mediane della concentrazione di
Risposta. E' noto che i valori di concentrazione di una sostanza nell'aria sovente hanno valori anomali, a causa delle correnti e della disposizione delle fonti. Con pochi dati e in una ricerca nuova, sono ignote le caratteristiche statistiche della popolazione da cui sono estratti i dati campionari. Nell'esempio riportato, anche la semplice lettura e la rappresentazione grafica dei dati sono in grado di evidenziare la non-normalità dei dati di alcune zone e la loro non omoscedasticità. Nel gruppo D, la presenza del valore 430 determina una varianza sensibilmente maggiore ed una distribuzione lontana dalla normalità (come tuttavia è necessario dimostrare con test adeguati, riportati in paragrafi successivi). Non è quindi possibile applicare l'analisi della varianza parametrica, ma si impone il ricorso al test di Kruskal-Wallis.
1 - I valori devono essere sostituiti dal loro rango, calcolato su tutte le osservazioni dei k gruppi a confronto. Da essi, si calcola la somma dei ranghi (Ri) ed il numero di osservazioni (ni) di ogni gruppo o campione.
2 - Con N = 22 e k = 4 si ottiene un valore di g
uguale a 17,35. 3 - La tabella dei valori critici con 3 gdl riporta - 7,82 alla probabilità a = 0.05, - 11,34 alla probabilità a = 0.01, - 16,27 alla probabilità a = 0.001. Pertanto, si può rifiutare l'ipotesi nulla, con una probabilità di commettere un errore di I° tipo inferiore a 0.001.
Per la sua applicazione corretta, il test di Kruskal-Wallis richiede che la misura utilizzata sia continua. Di conseguenza, non si dovrebbero avere valori identici; ma nella pratica sperimentale, per l’approssimazione della scala o dello strumento, può succedere che alcune siano uguali. In questo caso, con valori identici che occupano lo stesso rango la varianza campionaria è ridotta e diviene opportuno correggere il valore di g .
La correzione per misure ripetute (ties) aumenta il valore di g; quindi incrementa la probabilità di trovare differenze significative tra le mediane dei gruppi a confronto. Tuttavia l'effetto della correzione è quasi sempre trascurabile, quando le misure identiche sono meno di un quarto delle osservazioni e sono distribuite tra più ranghi.
Per ottenere il valore di g’ corretto, si deve dividere la quantità g calcolata per un fattore di correzione C
dove: - p è il numero di raggruppamenti con ranghi ripetuti, - c è il numero di ranghi ripetuti nel raggruppamento i-esimo, - N è il numero totale di osservazioni nei k campioni a confronto.
Un altro metodo di correzione per i ties è quello di Hinkley (che apporta variazioni maggiori sul risultato); è spiegato in un paragrafo successivo.
ESEMPIO 2. In una ricerca sulla qualità della vita, in tre quartieri (X, Y, Z) della stessa città sono stati ottenuti i punteggi di seguito riportati, con la medesima impostazione tabellare di un’analisi della varianza ad 1 criterio di classificazione.
Esistono differenze significative tra le loro mediane?
Risposta. Si devono sostituire i punteggi con i ranghi relativi e calcolare le somme, come nella tabella sottostante:
Da esse, con la formula
si stima il valore di g =
=
che risulta uguale a 9,848. Per 3 campioni di dimensioni 5, 5, 4 alla probabilità a = 0.001 il valore critico riportato nella tabella è uguale a 9,32. Di conseguenza, con probabilità P inferiore a 0.001 si rifiuta l’ipotesi nulla: esiste una differenza significativa tra le 3 mediane a confronto.
I dati presentano un numero elevato di ripetizioni: - il valore 2 e il valore 5 compaiono 2 volte; - il valore 4 e il valore 7 compaiono 3 volte. Il fattore di correzione C
con i dati dell’esempio risulta
1 -
1 - uguale a 0,97802 e il valore corretto di g (g’) g’ = 9,848 / 0,97802 = 10,069 diviene 10,069 (il precedente era 9,848).
Anche questo esempio dimostra che il fattore di correzione aumenta il valore di g, ma per entità trascurabili. Con questi dati la correzione non era necessaria, poiché il valore stimato era già significativo; tuttavia è stato applicato, per fornire una stima corretta di g. Come in tutte le correzioni per i ties, nell’indice di correzione un solo valore ripetuto molte volte ha un peso relativo maggiore di molti valori ripetuti poche volte. Come semplice dimostrazione si può stimare che, se nelle 14 osservazioni vi fosse stato un solo valore ripetuto 5 volte, il fattore di correzione C sarebbe stato
C = 1-
uguale a 0,95604 e il valore corretto di g g’ = 9,848 / 0,95604 = 10,301
uguale a 10,301 fornendo uno scarto superiore al precedente. L’esempio è solo teorico, in quanto con tanti dati identici come nel caso appena ipotizzato la validità del test è molto dubbia perché modifica la distribuzione delle probabilità, come evidenziato nei capitoli precedenti - per la distribuzione T nel caso di un campione, - per la distribuzione U nel caso di due campioni indipendenti.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||