|
trasformazionI dei dati; test per normalita’ e PER OUTLIER
13.14. TRATTAMENTO DEGLI OUTLIER: ELIMINARLI O UTILIZZARLI? COME?
Se esistono outlier, la distribuzione del campione non dovrebbe avere forma normale. Di conseguenza, sarebbe possibile utilizzare i test di normalità, anche per una verifica della possibile esistenza di outlier. Se gli outlier sono solo in una coda della distribuzione, come in medicina quando gli individui ammalati sono caratterizzati da valori molto più alti oppure molto più bassi della norma, possono essere utilizzati i test di simmetria. Ma, come tutti quelli per la normalità, questi test sono poco potenti. Di conseguenza, per scoprire gli outlier è vantaggioso utilizzare i metodi proposti in questo capitolo.
La difficoltà di individuare gli outlier in molte analisi di laboratorio ha suggerito l’utilizzazione di protocolli standard. In un testo di statistica non è possibile una loro presentazione generale, perché sono specifici di ogni singola disciplina e entro esse di ogni tipo di analisi. Una volta che sia stato dimostrato che un dato probabilmente è un outlier, nella letteratura si apre un altro dibattito interessante sul suo uso e sull’importanza che gli deve essere attribuita, per le analisi statistiche: L’outlier è il dato meno importante, quindi da eliminare, oppure è quello più importante, da analizzare con particolare attenzione e dal quale dipendono le decisioni? La risposta non è univoca: Dipende dal contesto.
Come esempio, nei testi di statistica applicata sono riportati due casi estremi, che possono essere frequenti nell’analisi chimica e più in generale nelle misure di laboratorio. Sono due casi tra loro identici come impostazione metodologica, ma che hanno scopi contrastanti e quindi conducono a decisioni opposte. Come primo caso, si supponga di voler misurare quale è la concentrazione di una sostanza presente in un prodotto industriale attraverso 5 campioni, per ottenere la media e la varianze più vicine alla realtà. Se tra essi è presente un outlier, il risultato di quel dato è interpretato come un probabile errore nella conduzione dell’esperimento, eventualmente determinato da variazioni ambientali indesiderate, delle quali non ci si è accorti: è eliminato e sia la media sia la varianza sono calcolate solamente sulle altre 4 misure. Come secondo caso, si ipotizzi di voler valutare l’attendibilità dello strumento nelle analisi precedenti. La presenza anche di un solo outlier lo rende inaffidabile: l’outlier diventa l’informazione più importante. Il rapporto di verifica sarà fondato su di esso e lo strumento sarà rifiutato perché poco attendibile.
Accertata l’esistenza di uno o più outlier, come comportarsi nell’analisi statistica? La prima risposta è la trasformazione dei dati, per ricostruire la normalità della distribuzione e la condizione di omoschedasticità, se i gruppi sono almeno due. Ma esistono altre scelte. Se le due risposte estreme, quali - eliminarli dal campione, - accettarli come gli altri ed effettuare l’analisi come se i dati fossero tutti corretti, sono considerate poco logiche, anche se applicate da molti, esistono vari altri modi per raggiungere un compromesso, - che da una parte non li elimini, perché esistono, - ma che dall’altra riduca il loro peso sull’informazione fornita da tutti gli altri dati della distribuzione.
I metodi più diffusi sono quattro: 1 – l’uso della mediana al posto della media, come misura di tendenza centrale, 2 – passare da una scala di rapporti o a intervalli a una scala di tipo ordinale, 3 – ricorrere al Trimming, 4 – ricorrere alla Winsorization.
I primi due metodi sono già stati presentati in varie situazioni e sono fondamentalmente la scelta di un test non parametrico. Analoghi a essi, sono il jackknife e il bootstrap, descritti in modo dettagliato in un capitolo successivo. Soprattutto il primo è in grado di evidenziare l’effetto del valore anomalo sulle statistiche della distribuzione, fornendo la statistica con esso e l’intervallo di confidenza della statistica senza di esso.
Il Trimming data, o semplicemente Trimming, è l’eliminazione di una percentuale fissa di valori estremi. Può essere fatta in entrambe le code o in una coda sola della distribuzione dei dati, sulla base delle caratteristiche del fenomeno. Anche la quota di estremi da eliminare è molto variabile, potendo essere - solo il valore più alto e quello più basso, - il primo e l’ultimo cinque per cento, - il primo e l’ultimo quartile (25%), - altre quote tra il minimo di un dato e il massimo di un quarto dei dati.
E’ relativamente frequente la scelta di prendere in considerazione solamente il 50% dei valori centrali, come appunto si ottiene eliminando il primo e l’ultimo quarto. La media di questa distribuzione è chiamata media interquartile e viene utilizzata quando la proporzione di outlier in entrambe le code è molto alta.
La Winsorization (la tecnica è chiamata winsorizing) presentata da vari autori di testi di statistica applicata, tra i quali W. J. Dixon e F. J. Massey con il testo del 1969 Introduction to Statistical Analysis (edito da McGraw-Hill, New York, a pagg. 330-332) non elimina i valori più estremi, ma li sostituisce con altri meno estremi.
E’ una tecnica semplice, che serve per attenuare l’effetto di possibili outlier, quando i dati raccolti servono per il calcolo delle statistiche del campione o per test successivi (A simple technique to soften the influence of possible outliers). Il numero di valori da prendere in considerazione ovviamente dipende
- da - e dalle caratteristiche della distribuzione.
Ad esempio, si supponga di avere ottenuto la seguente serie di 13 valori, qui ordinata
e la cui media è
E semplice rilevare dalla lettura dei dati, quindi a posteriori, che
sono presenti due valori molto differenti da tutti gli altri, in entrambi gli
estremi (i valori 0 e 1 nella coda sinistra; 154 e 322 nella coda destra). Può
essere utile costruire una nuova distribuzione, sempre di
la cui media è
La mediana delle due distribuzioni dei 13 valori è 18. Si osservi come
la seconda media (18,7) sia molto vicina alla mediana (18), che ovviamente è
rimasta immutata, mantenendo
Questo metodo è da utilizzare soprattutto quando sono presenti valori indefiniti (come < 1 oppure > 100). Sono misure che si riscontrano quando la variabilità delle quantità presenti nei campioni è nettamente inferiore oppure superiore al campo di misura dello strumento, che è preciso solo per valori intermedi. Il trimming può essere simmetrico, come in questo caso; ma può anche essere asimmetrico, quando l’operazione coinvolge un numero di dati differenti nelle due code della distribuzione.
Come nella scelta del test quando i metodi alternativi sono numerosi, anche in questa situazione dopo che sono state presentate varie metodologie si pone un problema: “Quale è l’operazione più appropriata, sia per identificare l’outlier, sia per effettuare test corretti in presenza di outlier?”. La risposta è data solo da una conoscenza della statistica che sia congiunta a una competenza ancora maggiore nella disciplina. Da questa ultima infatti dipendono - il valore da attribuire all’outlier, - la frequenza con la quale il fenomeno è atteso, - la scelta del tipo di scala nella sua misurazione.
Dalla competenza disciplinare dipende la decisione sulla esistenza stessa dell’outlier, poiché l’analisi statistica fornisce solo una probabilità. Infatti è sempre possibile avere un valore che è anomalo solo apparentemente, perché raro. Si ritorna alla soggettività della scelta, all’esperienza come fattore prevalente nella decisione, pure in presenza di tanti metodi rintracciabili nella letteratura statistica. Anche in questa serie di problemi, tra i meno schematizzati dell’analisi statistica, che vanno dalla individuazione degli outlier a quello della scelta del test più adatto per identificarli e infine alla decisione se eliminarli, si ritorna al problema più generale dell’interpretazione dei risultati dei test inferenziali. Essa dipende quasi totalmente dalla conoscenza della disciplina alla quale la statistica è applicata; il risultato del test assume vero significato solo nella successiva interpretazione disciplinare. La statistica fornisce solo un contributo di informazioni. Compete al ricercatore decidere sulla significatività o meno di una media, della varianza o di un qualsiasi altro parametro.
Si può concludere la discussione sugli outlier, rispondendo alle domande precedenti “Quale è l’operazione più appropriata, sia per identificare l’outlier, sia per effettuare test corretti in presenza di outlier?” con un’altra domanda: “La rilevazione e l’eventuale rimozione degli outlier per applicare un test parametrico è importante o trascurabile? Robert R. Sokal e F. James Rohlf, autori di uno dei testi internazionali più diffusi a livello di preparazione post-laurea, Biometry. The principles and practice of statistics in biological research (3rd ed. W. H. Freeman and Company, New York, XIX + 887 p.) scrivono (a pag. 407): Le conseguenze della non normalità degli errori (gli scarti dei valore dalla media) non sono molto gravi (The consequences of nonnormality of error are not too serious), poiché le medie hanno una distribuzione più vicina alla normale della distribuzione delle singole osservazioni, come conseguenza del teorema del limite centrale. Solamente distribuzioni fortemente asimmetriche possono avere effetti rilevanti sul livello di significatività di un test F o sull’efficienza del disegno sperimentale. Il modo migliore per correggere la perdita di normalità è effettuare una trasformazione che renda normale la distribuzione. Se la trasformazione non da risultati soddisfacenti, utilizzare test non parametrici. Tuttavia, spesso il problema è più complesso.
La scelta tra mantenere oppure eliminare l’outlier nelle analisi statistiche dipende dalla teoria che si vuole verificare, poiché ovviamente si desidera che il risultato del test coincida con la teoria che si vuole dimostrare. Come esempio, assumiamo un problema di psicologia: gli studenti migliori in matematica sono i migliori anche nell’apprendimento delle lingue?
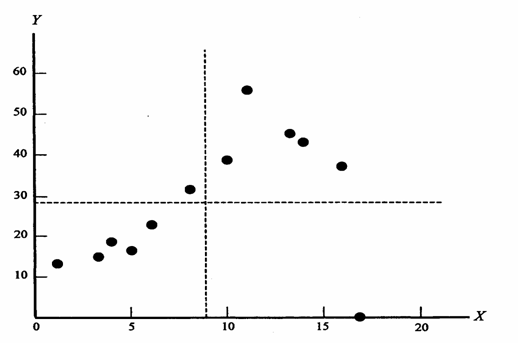
C’è chi afferma che gli studenti migliori in matematica sono tali perché più diligenti, logici e studiosi; quindi, con poche eccezioni, sono anche i migliori in tutte le altre discipline, tra cui lo studio della lingua. Ma appare ugualmente convincente anche la teoria opposta. Chi è portato alla logica matematica ha poca attitudine per l’apprendimento alle lingue; inoltre la conoscenza delle lingue straniere richiedono attività e impegni, come i viaggi, i soggiorni all’estero e i contatti con le persone, che male si conciliano con lo studio e la riflessione richiesti dalla matematica. Un esperimento con 12 studenti, che hanno svolto un compito di Matematica e una prova scritta di Lingua straniera, ha dato i seguenti risultati nel conteggio degli errori:
La rappresentazione grafica facilita la lettura del risultato complessivo ed evidenzia la presenza di un outlier.
E’ un problema di statistica bivariata, che sarà discussa in capitoli successivi. Ma i concetti sull’uso del’outlier sono identici. Si osserva che per undici giovani all’aumentare del numero di errori in matematica (X) aumentano anche quelli lingua. Il dodicesimo giovane è un outlier: di madre lingua parla meglio del docente, ma ha dovuto cambiare spesso scuola e in matematica è quello che ha commesso più errori. Se si analizzano solamente i primi dati con una correlazione parametrica (come l’r di Pearson) o meglio ancora una correlazione non parametrica (come il tau di Kendall o il rho di Sperman) si dimostra che esiste una correlazione positiva. Se l’outlier viene lasciato e si analizzano insieme i 12 dati, è tale il peso del punto anomalo che la teoria potrebbe essere rovesciata. Anche in questo caso, è importante la scelta del test, che può variare da una correlazione non parametrica classica al test della mediana di Blomqvist. Quale la scelta adeguata? Tutte. Sia separatamente, sia insieme. Purché adeguatamente motivate, sotto l’aspetto disciplinare e di metodologia statistica.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||