elementi di statistica descrittivaPer DISTRIBUZIONI UNIVARIATe
1.11. RAPPRESENTAZIONI GRAFICHE E SEMI-GRAFICHE DELLE DISTRIBUZIONI: DATA PLOT, BOX-AND-WHISKER, LINE PLOT, STEM-AND-LEAF
Per evidenziare le caratteristiche di una tabella o di un semplice elenco di dati, sono utili anche altre rappresentazioni grafiche o semigrafiche. Eccetto il box-and-whisker, possono essere costruiti con facilità, anche senza l’aiuto di programmi informatici. Nella terminologia internazionale, quelli di uso più comune sono A – data plot, B – box-and-whisker, C – line plot, D – stem-and-leaf.
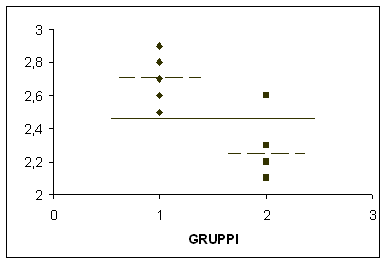
A – Il metodo più semplice e intuitivo è la rappresentazione del valore di ogni singolo dato con un punto: il data plot, chiamato anche dotplot. E’ un diagramma cartesiano, in cui - ogni singolo dato (data) è rappresentata da un punto (plot) o altro segno convenzionale che - sull’asse verticale indica il valore osservato, - e sull’asse orizzontale riporta il nome, il numero o un simbolo di identificazione del gruppo. Ad esempio, la figura
è il data plot della tabella
Nel grafico, il numero di punti risulta minore di quello dei dati riportati in tabella, perché alcuni hanno valori identici e quindi sono graficamente sovrapposti.
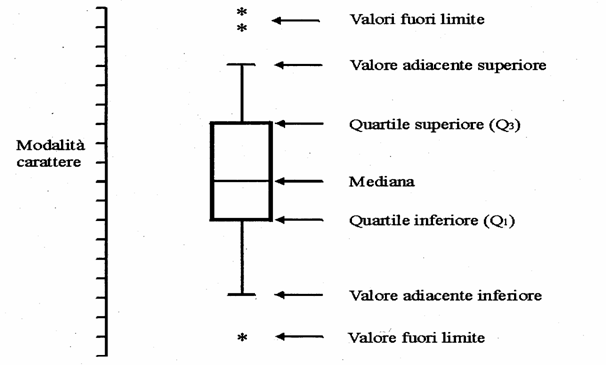
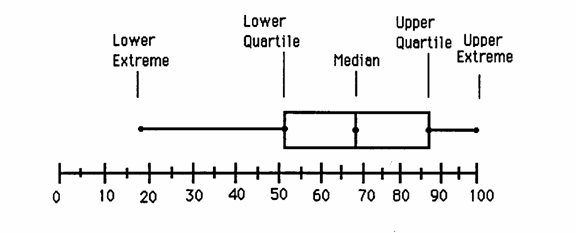
B - BOX-AND-WHISKER I diagrammi Box-and-Whisker (scatola-e-baffi), chiamati anche più rapidamente boxplot, sono stati presentati in modo organico per la prima volta da John W. Tukey nel suo testo del 1977 (Exploratory Data Analysis, pubblicato da Addison-Wesley, Reading, Mass.). Sono un metodo grafico diffuso recentemente e reso di uso corrente dai programmi informatici, che possono costruirlo con rapidità. La quantità di informazioni che forniscono è elevata. Molto più raramente, sono chiamati anche five number summary poiché, nella loro forme più semplice, riassumono in cinque numeri le informazioni contenute nella distribuzione: - la mediana, - il primo e il terzo quartile; - il valore minimo e quello massimo.
Figura 27. Box-and-Whisker come proposto da Tukey nel 1977.
Servono per rappresentare visivamente quattro caratteristiche fondamentali di una distribuzione statistica di dati campionari: 1 - la misura di tendenza centrale, attraverso la mediana e/o la media; 2 - il grado di dispersione o variabilità dei dati, rispetto alla mediana e/o alla media; 3 – la forma della distribuzione dei dati, in particolare la simmetria; 4 – sia la semplice presenza che l'individuazione specifica di ogni valore anomalo o outlier.
Secondo il metodo proposto da Tukey nel 1977, riportato nella figura precedente con i termini in italiano, un diagramma Box-and-Whisker o boxplot è costruito a fianco di una scala, che riporta le modalità o i valori del carattere. La sua realizzazione richiede una serie di passaggi logici, che può essere riassunta in uno schema composto da 8 punti, dalla quali derivano gli elementi metodologici:
1 - Ha origine da una linea orizzontale, interna alla scatola, che rappresenta la mediana (median).
2 - La scatola (box) è delimitata da due linee orizzontali: - la linea inferiore, indicata con Q1, che rappresenta il primo quartile o quartile inferiore (lower quartile oppure più raramente lower fourth); - la linea superiore, indicata con Q3, che rappresenta il terzo quartile o quartile superiore (upper quartile o più raramente upper fourth). Quartiles e fourths nel linguaggio di Tukey non sono esattamente sinonimi: i fourths sono quartili approssimati, che segnano i limiti del box. Ma sono distinzioni spesso ignorate, nel linguaggio scientifico più diffuso nella statistica applicata.
3 - La distanza tra il terzo (Q3) e il primo quartile (Q1), detta distanza interquartilica (interquartile range o IQR), è una misura della dispersione della distribuzione. E’ utile soprattutto quando sono presenti valori anomali, poiché - tra il primo e il terzo quartile (Q3 - Q1) per costruzione sono compresi il 50% delle osservazioni collocate intorno al valore centrale. Un intervallo interquartilico piccolo indica che la metà delle osservazioni ha valori molto vicini alla mediana. L’intervallo aumenta al crescere della dispersione (varianza) dei dati. Inoltre, esso fornisce informazioni anche sulla forma della distribuzione (soprattutto sulla simmetria): - se la linea inferiore e la linea superiore della scatola (cioè Q1 e Q3) hanno distanze differenti dalla mediana, la distribuzione dei valori è asimmetrica.
4 - Le linee che si allungano dai bordi della scatola e che si concludono con altre due linee orizzontali, i baffi (whiskers), delimitano gli intervalli nei quali sono collocati - i valori minori di Q1 (nella parte inferiore) - e quelli maggiori di Q3 (nella parte superiore). Questi punti estremi, evidenziati dai baffi, in italiano spesso sono chiamati valori adiacenti.
5- Indicando con r la differenza interquartilica
si definiscono le quantità che individuano - il Valore Adiacente Inferiore (VAI), definito come il valore osservato più piccolo che sia maggiore o uguale a Q1 - 1,5r: VAI ³ Q1 - 1,5r
- il Valore Adiacente Superiore (VAS) definito come il valore osservato più grande che risulta minore o uguale a Q3 + 1,5r: VAS £ Q3 + 1,5r
Una attenzione particolare deve essere posta alla quantità 1,5 delle due formule, per calcolare il VAI e il VAS. E’ stato proposto da Tukey, ma non ha particolari proprietà. Alla domanda del perché avesse indicato 1,5 e non un altro valore, la risposta di Tukey è stata che la sua scelta era fondata sulla sua esperienza, sul suo “buon senso” statistico.
6 - Se i due valori estremi sono contenuti entro l’intervallo tra VAI e VAS, i due baffi rappresentano i valori estremi e nei dati raccolti non sono presenti valori anomali.
7 - I valori esterni a questi limiti sono definiti valori anomali (outliers). Nella rappresentazione grafica del box-plot, gli outliers sono segnalati individualmente, poiché - costituiscono una anomalia importante rispetto agli altri dati della distribuzione - e nella statistica parametrica il loro peso sulla determinazione quantitativa dei parametri è molto grande. I valori che - si discostano dalla mediana tra 1,5 e 3 volte la distanza interquartile possono essere considerati nella norma, - mentre quelli che si discostano oltre 3 volte la distanza interquartile dovrebbero essere molto rari e meritano una verifica ulteriore, per distinguere con sicurezza gli outliers da quelli che possono essere stati determinati da banali errori di misura o di trascrizione. Gli ipotetici outlier dovrebbero essere sempre verificati, per capire le cause che li hanno determinati e quindi apportare le eventuali correzioni, se si trattasse di errori effettivi.
8 - Anche i due valori adiacenti (VAI e VAS), con la loro distanza dai quartili Q1 – VAI e VAS – Q3 forniscono informazioni - sia sulla variabilità dei dati sia sulla la forma della distribuzione. Se la distribuzione è normale, - nel box-plot le distanze tra ciascun quartile e la mediana saranno uguali - e avranno lunghezza uguale le due linee che partono dai bordi della scatola e terminano con i baffi. In una distribuzione normale, i due baffi (whiskers) distano dalla mediana (me) una quantità pari a 2,69796 volte la deviazione standard (s). Questo intervallo comprende il 99,3% delle osservazioni e per valori estremi ha
I diagrammi Box-and-Whiskers hanno avuto una serie di adattamenti e evoluzioni. Tra le versioni più diffuse nei programmi informatici internazionali, sono da ricordare due tipi: - quelli che impiegano la mediana come valore di tendenza centrale ed utilizzano la distribuzione dei quartili o dei percentili e si rifanno al modello descritto; - quelli che riportano la media, insieme con l’errore standard e la deviazione standard.
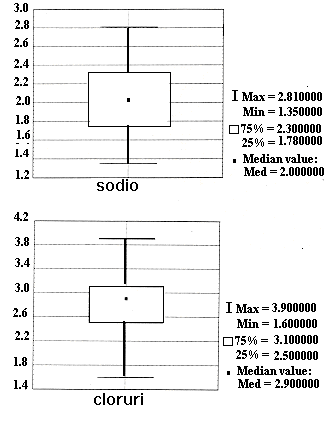
I primi forniscono una descrizione non parametrica della forma della distribuzione, evidenziando dispersione e simmetria. I secondi rappresentano indici parametrici, presupponendo una distribuzione normale. Essi evidenziano sia la dispersione dei dati sia quella della media campionaria (questi argomenti saranno trattati in modo dettagliato quando si discuterà l’intervallo fiduciale o di confidenza). Nei due Box-and-Whisker della figura 28, il valore di riferimento centrale è la mediana, la scatola delimita il primo ed il terzo quartile, mentre i baffi individuano il valore minimo e quello massimo. Le due distribuzioni non sono perfettamente simmetriche: la loro mediana non è equidistante dal 1° e dal 3° quartile, individuato dall’altezza della scatola, né dal valore minimo e massimo, rappresentato dai baffi.
Figura 28. Box-and-Whisker con misure non parametriche, utilizzando una distribuzione di dati.
La distribuzione dei dati del sodio (i cui valori dettagliati sono riportati nell’ultimo paragrafo di questo capitolo) ha una asimmetria positiva o destra, mentre la distribuzione dei valori dei cloruri (riportati stessa tabella) ha una asimmetria sinistra o negativa. La rappresentazione in istogrammi e la misura del grado di asimmetria descrivono una lieve alterazione rispetto ad una distribuzione perfettamente normale.
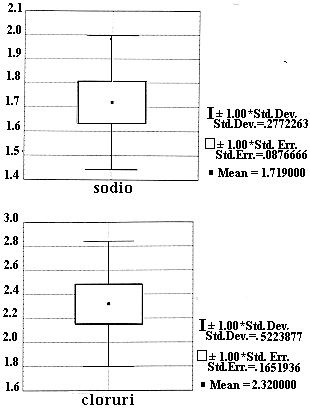
Nei due boxplot della figura 29, il valore di riferimento è la media, la scatola riporta la distanza dell’errore standard e i baffi indicano una distanza di una deviazione standard. Sono misure parametriche di dispersione rispettivamente della media e delle singole osservazioni, che saranno discusse dopo la presentazione della distribuzione normale e del test t di Student. I baffi (whisker) riportano gli estremi che comprendono circa i 2/3 della distribuzione dei dati, mentre la scatola (box) fornisce gli estremi che comprendono i 2/3 delle medie che hanno identica variabilità.
Figura 29. Box-and-Whisker con misure parametriche.
Una forma più complessa, specifica per evidenziare gli outlier in una distribuzione di dati, è riportata nel capitolo dedicato in parte alle metodologie specifiche per individuare statisticamente gli outliers. Nella pagina seguente, come applicazione di un esempio a partire dai dati rilevati, è riportato uno dei metodi più semplici di costruzione manuale di un generico Box-and-Wiskers. Il diagramma Box-and-Wiskers può essere costruito indifferentemente in modo verticale, come i precedenti, oppure in modo orizzontale, come il successivo. Il primo metodo è più frequente, in quanto facilita il confronto tra due o più grafici
ESEMPIO 1. Con la seguente serie di 15 dati,
il Box-and Whiskers Plot risulta
Figura 30. Box-and-Whishers Plot non parametrico
Per la sua costruzione, la serie di passaggi logici è:
1 - Dopo aver ordinato i valori in modo crescente, allo scopo di semplificare le operazioni richieste dal metodo
2 - si identifica la mediana che, su 15 dati, è esattamente l’ottavo valore: Mediana = 68
3
– Considerando solo la prima metà, i sette valori minori della
mediana, si individua la loro nuova mediana, che rappresenta il primo quartile
(
è esattamente il quarto valore: Primo quartile = 52
4
– Considerando solo la seconda metà, i sette valori maggiori della
mediana, si individua la loro nuova mediana, che rappresenta il terzo quartile
(
è esattamente il quarto valore Terzo quartile = 87
La scelta della mediana e dei due quartili è stata semplice poiché i dati utilizzati sono sempre risultati dispari: se fossero stati pari, come nel caso seguente
la mediana relativa sarebbe caduta tra il terzo valore (85) e il quarto (87); quindi identificata dalla loro media: 86.
5 – Dalla differenza tra il terzo e il primo quartile si ricava la distanza interquartile (interquartile range o IQR) distanza interquartile (IQR) = 87 – 52 = 35
6 – Infine di individuano i due estremi: - il valore minimo o estremo inferiore (lower estreme) è 30; - il valore massimo o estremo superiore (upper extreme) è 100.
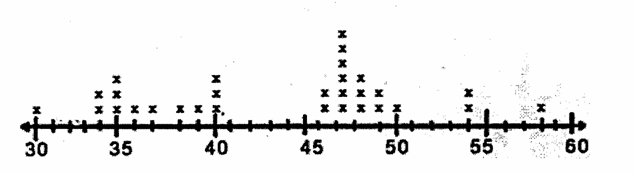
C – LINE PLOT Un secondo tipo di rappresentazione semigrafica è il diagramma a linee o line plot, in italiano più frequentemente chiamato diagramma a barre. Esso rappresenta il modo più facile e immediato per organizzare i dati. La sua costruzione è molto semplice: - la linea orizzontale rappresenta i valori rilevati, riportati in modo completo e ordinati dal minore al maggiore; - ogni valore rilevato è individuato da una X, riportato in corrispondenza del valore rappresentato sull’asse orizzontale; il numero di X corrispondente a ogni punteggio indica quante volte un valore compare tra quelli rilevati.
ESEMPIO 2. Dai seguenti 30 valori
per costruire il line plot
Figura 31. Line plot della tabella precedente
si richiede la serie di passaggi logici seguente:
1 – dopo aver ordinato i dati per rango
2 – si conta quante volte compare ogni valore, compreso tra il minimo e il massimo. Minimo e massimo del grafico, allo scopo di descrive un intervallo completo, possono iniziare prima del valore più basso e terminare dopo il valore più alto tra quelli che sono stati effettivamente osservati.
D – STEM-AND-LEAF Il diagramma a ramo e foglia (stem-and-leaf plot, stem-and-leaf display) è un terzo tipo di tecnica semi-grafica, che può essere descritta come un incrocio tra un istogramma e una tabella di frequenza. E’ chiamata, più brevemente, pure stem-plot o stemplot. Anche questa metodologia è stata presentata in modo organico da John W. Tukey nel suo testo del 1977 Exploratory Data Analysis (pubblicato da Addison-Wesley, Reading, Mass.). E’ parimenti riportata in molti programmi informatici dell’ultima generazione. E' una diffusione tra gli utenti della statistica che ha alimentato anche la richiesta di conoscenza dei concetti sui quali questi metodi sono fondati. Il metodo è utile per una prima descrizione di una distribuzione di dati. Inoltre, può essere di aiuto anche per valutare il livello di precisione con il quale i dati sono stati raccolti. La figura seguente
Figura 32 - A stem-and-leaf plot for the height of 351 elderly woman
è un esempio tratto dal volume (pag. 363) di B. S. Everitt del 2002 The Cambridge Dictionary of Statistics (2nd edn. Cambridge University Press, UK, IX + 410 p.).
Il grafico stem-and-leaf può essere utilizzato sia per variabili discrete sia per variabili continue. E’ simile a un grafico a barre.
I principi di costruzione sono semplici: - ogni numero è diviso in due parti: il ramo (stem) e la foglia (leaf): - il ramo è il numero, collocato a sinistra, che include tutte le cifre eccetto l’ultima; - la foglia, collocata a destra, è sempre un numero con una cifra sola (single digit), che può essere esclusivamente l’ultima di tutto il numero.
Anche questo grafico ha lo scopo di mostrare le caratteristiche fondamentali di una distribuzione di dati: - valore minimo e massimo e quindi l’intervallo di variazione, - i valori più frequenti o più comuni, - la presenza di uno o più picchi, - la forma della distribuzione, in relazione soprattutto alla simmetria, - la presenza di outlier o valori anomali, quelli troppo distanti dal gruppo principale di valori.
Le modalità di organizzazione dei dati in grafici stem-and-leaf variano in funzione dei diversi modi con i quali i dati possono essere stati rilevati: - con una sola cifra oppure con più cifre, - numeri solo interi oppure con uno o più decimali.
Hanno il vantaggio pratico di potere essere costruiti, nel passato, con una macchina da scrivere. Attualmente, con un programma di video-scrittura, senza ricorrere all’uso di programmi statistici di elaborazione dei dati. Gli esempi successivi illustrano casi differenti, per le caratteristiche sia dei valori rilevati sia della loro distribuzione di frequenza. L’applicazione dei principi prima enunciati richiede soluzioni tecniche diverse, in funzione delle differenti situazioni sperimentali.
ESEMPIO 3. Si assuma di aver effettuato 30 rilevazioni della concentrazione di CO (mg/mc) lungo una strada con traffico, riportati in modo ordinato e crescente nella tabella seguente:
Per costruire un diagramma stem-and leaf è utile seguire alcuni passaggi logici e metodologici.
1 - Dapprima nei valori rilevati si devono individuare le cifre che formano gli stem e i valori che formano le leaf: - i primi sono quelli che danno una misura approssimata del fenomeno, in questo caso, la parte intera del valore rilevato; - i secondi sono quelli che rendono la stima più precisa, in questo caso i valori decimali, poiché ne è stato rilevato solamente uno. 2 – Successivamente, i valori stem sono ordinati modo crescente lungo un’asse verticale, riportando anche le classi vuote. 3 – Le cifre che formano le leaf sono riportate in ordine crescente lungo l’asse orizzontale, costruito lateralmente ai valori stem.
La disposizione dei numeri assume la forma della figura successiva, che ha l’aspetto grafico di una tabella:
E’ una specie di istogramma il cui l’asse delle ascisse è verticale e quello delle ordinate, nel quale sono riportate le frequenze, è orizzontale. Rispetto ad esso, spesso è caratterizzato da un numero di classi differente da quello richiesto per un istogramma corretto. Nella costruzione di un stem-and-leaf abitualmente non si pone particolare attenzione a questo aspetto, che invece è di importanza rilevante nell’istogramma, che dovrebbe assumere forma normale.
In questa rappresentazione grafica, - l’altezza di ogni classe è fornito dal numero di decimali riportati di fianco alla parte intera, che corrisponde al totale delle leaves rilevati per lo stesso stem.
La lettura dettagliata della rappresentazione semigrafica riportata nella pagina precedente permette di ricavare varie informazioni, che è utile elencare in modo dettagliato: 1 - l’intervallo di variazione del fenomeno: da 6 a 22; 2 - gli stem modali: i valori 10 e 11; 3 - la mediana: tra 10,5 e 10,7 trattandosi di 30 dati (quindi un numero pari); 4 - i quantili più utili ad una descrizione dettagliata: l’80% dei valori è compreso tra 8,7 (il 10° percentile) e 20,5 (il 90° percentile); 5 - la forma della distribuzione: fortemente asimmetrica a destra (nei valori alti) e forse bimodale; 6 - la presenza di outliers (valori anomali rispetto alla distribuzione; se essi distano molto dagli altri stem, non è necessario riportare tutti i valori stem intermedi); 7 - la precisione con la quale i dati sono stati rilevati: gli ultimi 4 valori sembrano arrotondati alla mezza unità (terminano infatti con 0 e 5), mentre i primi sembrano stimati con una precisione al decimale (sono infatti presenti tutti i valori da 1 a 9).
La costruzione di un diagramma stem-and-leaf deve essere adattata alle dimensioni del campione e alle caratteristiche dei dati raccolti. Ad esempio, sempre nella misura della qualità dell’aria, i valori guida o livelli di attenzione sono da 100-150 mcg/mc come valore medio di 24 ore per SO2. Le misure possono quindi essere approssimate all’unità; di conseguenza, gli stem possono essere indicati dalle decine e le leaf dalle unità. Se i dati sono stati raccolti con troppa approssimazione, ad esempio i dati di CO rilevati con arrotondamento dell’unità, non è più possibile costruire un diagramma come quello presentato. Non sempre a posteriori è possibile costruire questo diagramma. Simmetricamente, se i dati sono raccolti con precisione eccessiva rispetto alla loro variabilità, ad esempio i valori di CO alla seconda cifra decimale, risulta necessario arrotondarli.
Gli esempi seguenti, sono tratti da indicazioni dei manuali di programmi informatici accessibili gratuitamente in internet.
ESEMPIO 4. Con la seguente serie di dati
costruire lo stem-and-leaf:
ESEMPIO 5. Con la seguente serie di dati
costruire lo stem-and-leaf:
Quando gli stem sono pochi, per ottenere una distribuzione di frequenza che riesca a descrivere almeno le caratteristiche più importanti della distribuzione di frequenza, è possibile e vantaggioso raddoppiarli, come è stato fatto in questo grafico. Poiché gli intervalli degli stem sono uguali, le leaf hanno uguali possibilità di cadere nei due stem.
ESEMPIO 6. Con la seguente serie di dati
si può costruire A - sia lo stem-and-leaf:
B - sia il successivo stem-and-leaf che, per le caratteristiche dei dati, appare preferibile:
Anche in questo caso gli stem sono pochi, per ottenere una distribuzione di frequenza sufficiente mete dettagliata. E’ conveniente raddoppiarli come in questo grafico, in cui tutte le leaf hanno uguali possibilità di essere attribuite ai vari stem.
ESEMPIO 7. Con la seguente serie di dati, che contengono decimali,
si ottiene lo stem-and-leaf:
Anche in analisi più complesse, i tre metodi presentati permettono il confronto tra distribuzioni differenti. Inoltre, in particolare quando i dati sono numerosi, essi sostituiscono la distribuzione dei valori campionari.
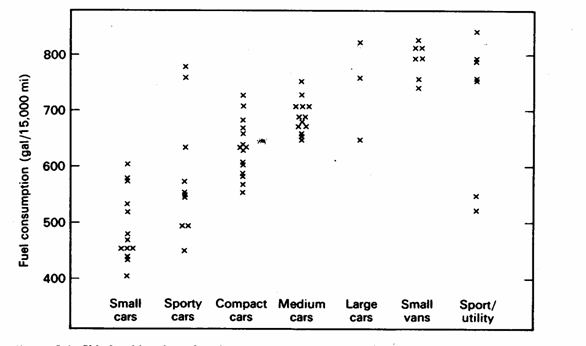
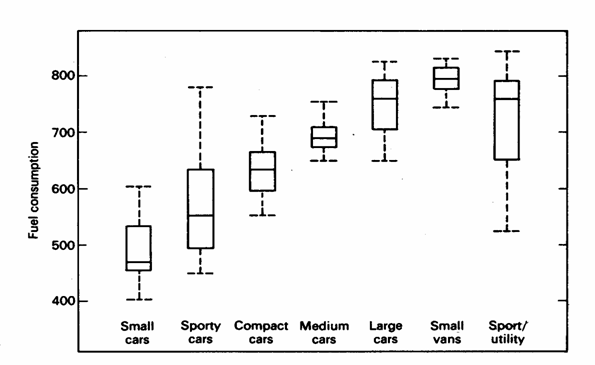
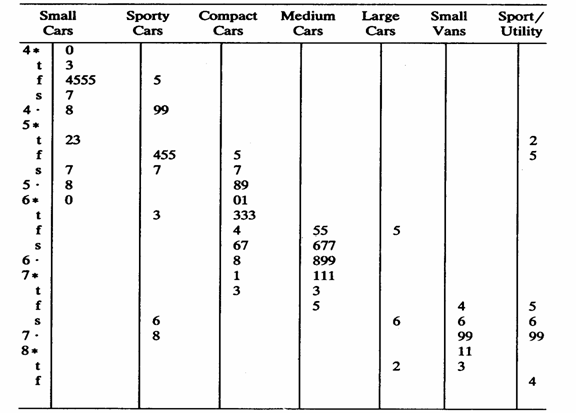
Per un riassunto dei metodi illustrati e un per confronto tra le potenzialità descrittive delle diverse caratteristiche delle distribuzioni dei dati, con il metodo - dei data plots, dei box-and-whisker plots e degli stem-and-leaf dispalys sono riportate le tre figure successive, tratte dal testo del 1991 di David Caster Hoaglin (nato nel 1944, della Harvard University), Frederick Mosteller (nato nel 1916, della Harvard Univerity) e John W. Tukey (nato nel 1915, della Princeton University) intitolato Fundamentals of Exploratory Analysis of Variance (A Wiley-Interscience Publication, John Wiley $ Sons, Inc. New York, XVII + 430 p.). I dati sono stati pubblicati dalla rivista Consumer Reports, April 1990, (pp.: 234-257). I tre metodi sono anche utili indicazioni di come è possibile pubblicare i dati originali, in alternativa alla tabelle.
Nell’esempio riportato, si tratta dei galloni di carburante necessari per percorrere 15.000 miglia. Il consumo è stato stimato per 1990 auto, classificate in 7 categorie, sulla base di una estrapolazione fondata sui dati raccolti in test standard di guida. Seppure con forme differenti, che evidenziano diversamente le caratteristiche della stessa distribuzione dei dati, la semplice lettura di ognuno dei tre grafici mostra: 1 - il consumo medio nettamente minore delle smalls cars e quello chiaramente maggiore delle ultime tre categorie; 2 - la diversa variabilità delle sette categorie di auto: la seconda categoria (sporty cars) e la settima (sport/utility) hanno una variabilità nettamente maggiore, in particolare se contrapposta a quella della categoria quattro (medium cars) e sesta (small vans). 3 - poiché le categorie sono state ordinate su una scala di rango della cilindrata, si evidenzia una tendenza sistematico all'aumento dei valori medi e mediani, passando dalle categorie inferiori (a sinistra) a quelle superiori (a destra).
Figura 33. Data plot o dotplot
Figura 34. Box and whisker
Figura 35. Stem and leaf La figura stem and leaf è una ulteriore variazione dei due modelli presentati: le dieci possibili foglie (leaves) sono classificate in cinque gruppi, indicati da simboli differenti: - le foglie 0 e 1 con il simbolo * (asterisco), - le foglie 2 e 3 con il simbolo t (lettera t), - le foglie 4 e 5 con il simbolo f (lettera f), - le foglie 6 e 7 con il simbolo s (lettera s), - le foglie 8 e 9 con il simbolo · (punto).
A conclusione della presentazione di questi metodi di rappresentazione grafica e semigrafica, è utile riportare l’avvertenza dei tre autori citati sull’uso di programmi informatici, in particolare nella costruzione di box-plots, ma estensibile a tutti i metodi: - spesso forniscono una impressione errata dei dati; - per una impostazione corretta, è sempre necessario leggere attentamente la documentazione che accompagna il software.
Segnalando l’articolo di M. Frigge, D. C. Hoaglin e B. Iglewicz del 1989 Some implementation of the boxplot (pubblicato su The American Statistician Vol. 43, 50-54), Hoaglin, Mosteller e Tukey nel loro articolo prima citato, dopo aver illustrato il modello standard di box and whiskers, affermano (pag. 45): Some popular computer software produces boxplots that depart from the above standard in unexpected ways. To avoid getting a mistaken impression of the data, it may be necessary to check the documentation that accompanies the software.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |