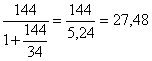|
INFERENZA SU UNA O DUE MEDIE CON IL TEST t DI STUDENT
6.13. CORREZIONE PER IL CAMPIONAMENTO IN UNA POPOLAZIONE FINITA E IL CONCETTO DI SUPERPOPOLAZIONE
Nel modello classico dell’inferenza statistica, la popolazione è composta da un numero infinito di dati; per quanto grande, il campione da essa estratto ne rappresenta una frazione prossima allo zero. In vari settori della ricerca applicata, succede che il numero di individui che formano la popolazione, oggetto dell’indagine, in realtà sia composto solo da alcune decine di individui, al massimo da poche centinaia. In biologia e in medicina, è il caso dei portatori di malattie rare: poche decine di persone in una regione, difficilmente rintracciabili nella loro totalità. Nella ricerca ambientale, è il caso dei laghi di una provincia, delle discariche di una regione, dei pozzi d’acqua potabile gestiti da un acquedotto. Per ridurre i costi e i tempi, per superare la difficoltà oggettiva di rintracciare tutti i soggetti utili all’analisi, può essere conveniente limitare i prelievi ad un campione, ovviamente con la possibilità di estendere i risultati a tutto l’universo, mediante l’inferenza.
In termini tecnici, quando il campione di n osservazioni rappresenta una quota non trascurabile della popolazione di N individui, per convenzione consolidata maggiore del 5%, si parla di campionamento in una popolazione finita (sampling a finite population). Per quanto attiene la media, è intuitivo che
- quanto più n si avvicina ad N,
tanto più
Nel caso in cui si analizzino tutti gli individui che compongono la popolazione, si afferma che
Di conseguenza, l’errore standard (es)
della media
campionaria
es =
deve essere ridotto, mediante - la correzione per la popolazione finita (finite population correction),
Nelle tre formule analoghe, più frequentemente citate nei testi l’errore standard diviene
es =
dove
-
-
Anche dalle formule, è semplice dedurre che - quando n è uguale a N, l’errore standard es diventa 0; cioè
- la media
campionaria
Pure nel caso di una popolazione finita, è possibile stimare quanti dati sono necessari, per ottenere la media con la precisione prefissata. Secondo il metodo proposto da W. G. Cochran nel 1977,(vedi: Sampling Techniques, 3rd. ed. John Wiley, New York, 428 pp. pagg. 77-78) - dapprima si stima n’ come se il calcolo fosse riferito ad una popolazione infinita,
(vedi paragrafo 10 ed esempio 1 di questo capitolo) - successivamente si passa alla sua stima corretta n con il rapporto
n =
dove - N è il numero di individui che formano la popolazione.
ESEMPIO 1. In molte zone, durante gli ultimi decenni la qualità delle acque sotterranee è peggiorata, per la diffusione sempre maggiore di fonti d’inquinamento, quali insediamenti civili e industriali, allevamenti zootecnici, pratiche agricole intensive, scarico di reflui. La concentrazione in nitrati spesso supera il limite di legge imposto per le acque potabili, fissato dal DPR 236/88 in 50 mg/l; quasi sempre supera la soglia d’attenzione. Una analisi dettagliata, condotta su tutti i 36 pozzi che alimentano l’acquedotto di una città, ha dato un valore medio pari a 47,8 mg/l. Dopo un’azione di risanamento, basata sul controllo degli allevamenti zootecnici e lo scarico di reflui, a distanza di tempo con una indagine rapida sono stati prelevati campioni da 12 pozzi, sui 34 attivi: la loro media è risultata pari a 47,1 mg/l con una varianza uguale a 2,54. A) Si può dimostrare che la quantità media di nitrati è diminuita? B) Quale è l’intervallo fiduciale della media della seconda rilevazione alla probabilità del 95%?
Risposta A) La quantità media di nitrati (mg/l) calcolata con un prelievo in tutti i 36 pozzi è la media reale, riferita alla prima rilevazione: m = 47,8 La seconda analisi condotta su 12 pozzi dei 34 attivi ha fornito
- una media
campionaria - che rappresenta solo una stima della media reale m0 alla seconda rilevazione.
Per verificare se la quantità media di nitrati è diminuita, quindi per scegliere tra l’ipotesi nulla H0: m0 = m oppure H0: m0 = 47,8 e l’ipotesi alternativa unilaterale H1: m0 < m oppure H1: m0 < 47,8 si dovrebbe applicare il test t di Student per un campione
t(n-1) =
se esso fosse stato estratto da una popolazione teoricamente infinita. Ma, trattandosi di un campione di 12 unità estratto da una popolazione di soli 34 pozzi, si deve apportare la correzione per una popolazione finita. Pertanto, il test diventa
t(n-1) =
Con i dati dell’esempio, - se la popolazione fosse stata infinita
t11 =
si sarebbe ottenuto un valore di t = –1,522 con 11 gdl - con un popolazione composta in totale di 34 individui
t11 =
si ottiene un valore di t = -1,892 con 11 gdl. Poiché il valore di t con 11 gdl, per un test unilaterale - alla probabilità a = 0.05 è uguale a 1,7959 - alla probabilità a = 0.01 è uguale a 2,7181 con la correzione per una popolazione finita, il test è significativo ad una probabilità a < 0.05.
B) Per stimare l’intervallo fiduciale entro il quale, alla probabilità prefissata, si trova la media reale m della seconda rilevazione, si deve utilizzare
Con i dati dell’esempio e con la solita simbologia, poiché il valore di t per un test bilaterale, alla probabilità 0.05 e con 11 gdl, è uguale a 2,201 si stima che la media reale m si troverà
entro un intervallo di più o meno 0,814 intorno alla media campionaria di 47,1. Poiché la media precedente, uguale a 47,8 è compresa entro questo intervallo, tra le due medie non esiste una differenza significativa, se si conduce un test bilaterale.
Se anche la seconda analisi fosse stata condotta su tutti i 34 pozzi che al momento formavano la popolazione, avremmo ottenuto direttamente il suo valore m. Per verificare una diminuzione della quantità media di nitrati rispetto alla prima rilevazione, sarebbe sufficiente il solo confronto tra le due medie, poiché il loro errore standard sarebbe uguale a 0.
ESEMPIO 2. Se il ricercatore avesse voluto dimostrare significativa una diminuzione di 0,5 mg/l alla probabilità a = 0.01 quanti pozzi avrebbe dovuto campionare dei 34 che formano la popolazione?
Risposta. Dalla formula generale
in cui - d = 0,5 e s2 = 2,54 - poiché t per un test unilaterale alla probabilità a = 0.01 con n scelto, in prima approssimazione, uguale a 30 è uguale a 2,4573 si ottiene
una prima stima n’ = 155,84 cioè 156 dati.
Essendo molto diverso dai 31 preventivati con n = 30, - dopo aver scelto il nuovo valore di t che per un test unilaterale alla probabilità a = 0.01 con n = 150 (poiché le stime diventano approssimate e i valori di t tra loro sono molto simili) è uguale a 2,3515 si effettua una seconda stima
che conduce a n’ = 142,68 cioè 143 dati.
Poiché l’ultimo valore stimato (143) è differente dal precedente (156), si può effettuare un terzo tentativo, che ha significato solamente per n = 140; infatti se scegliessimo lo stesso valore di t (2,3515) precedente per n = 150 otterremmo la stessa stima di n’. Con un valore di t, per un test unilaterale alla probabilità a = 0.01 con n = 140 uguale a 2,3533 si perviene alla terza stima
dove - n’ = 143,12 cioè 144 dati, confermando la seconda stima.
Questo valore è chiaramente assurdo, date le dimensioni complessive della popolazione (N = 34); comunque sia il suo valore, n’ deve essere corretto, essendo riferito ad una popolazione finita. Con
n =
si ottiene
n =
una stima di n uguale a 27,48 arrotondato a 29 dati
Se la domanda fosse stata: “Quanti dati servono per misurare la media della seconda rilevazione con un errore massimo di 0,5mg/l?” la procedura sarebbe stata identica a quella appena illustrata, però utilizzando un valore di t bilaterale. Con il numero di dati stimati, alle stesse condizioni l’intervallo fiduciale sarebbe risultato alla differenza stimata.
L’approccio presentato è quello classico. I concetti e i calcoli illustrati portano alla conclusione che, quando l’analisi è estesa all’universo dei dati, cadono - sia il concetto di “significatività statistica” - sia quello di distribuzione di probabilità. L’inferenza diviene teoricamente superflua, poiché i valori e le differenze riscontrate sui dati dell’universo non hanno bisogno d’inferenza, essendo quelli reali o della popolazione: sono significativi per definizione, per quanto essi siano piccoli.
Tuttavia, vari statistici enunciano concetti differenti. A loro parere, ai fini dell’analisi statistica spesso risulta utile ed opportuno considerare i dati della popolazione come frutto di un campionamento casuale semplice di una superpopolazione. Il gruppo può cambiare continuamente nel tempo, come la comunità di un paese o gli animali che vivono in un territorio, per nuove nascite, decessi e migrazioni. I pozzi che formano l’universo di quelli utilizzati in certo momento dall’acquedotto non sono sempre gli stessi, potendo essere ciclicamente sostituiti, con la disattivazione di alcuni e l’attivazione di altri.
Gli individui che formano una popolazione finita possono essere considerati come un campione casuale di una superpopolazione di numerosità ignota. Sulla base di tale assunzione, questi statistici ritengono che tutti gli strumenti inferenziali ritrovano il loro significato corretto, anche in una popolazione finita. La precedente correzione per campioni estratti da popolazioni finite sarebbe superflua o addirittura errata. L’idea di superpopolazione è un artificio che ad alcuni non appare in contrasto con considerazioni statistiche sostanziali; è adottato con frequenza, tanto che quando si utilizzano i dati di tutta la popolazione da molti è comunemente accettato il ricorso a test statistici con le formule presentate nella prima parte del capitolo, senza necessità di ricorrere alle correzioni proposte in questo paragrafo. I testi classici consigliano la correzione, come presentata in questo paragrafo.
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |
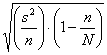
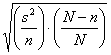
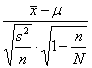
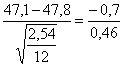 = - 1,522
= - 1,522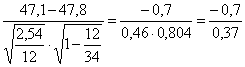 = - 1, 892
= - 1, 892