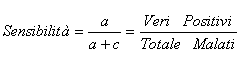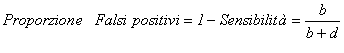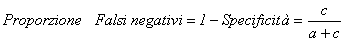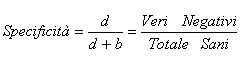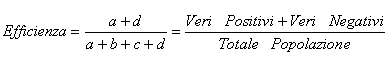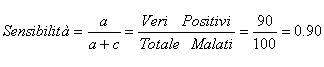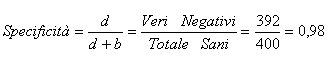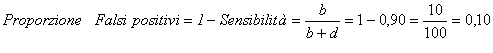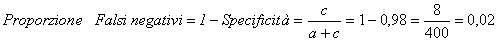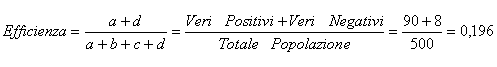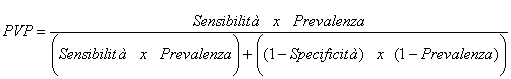PROPORZIONI E PERCENTUALI, RISCHI, ODDS E TASSI
5.2. ALTRI TERMINI TECNICI: SENSIBILITA’, SPECIFICITA’, VALORE PREDITTIVO E EFFICIENZA DI UN TEST O DI UNA CLASSIFICAZIONE.
Anche per valutare la prestazione o il rendimento (performance) di un test diagnostico e/o di una analisi qualitativa si utilizzano concetti e metodi che sono collegati all’uso di proporzioni. A questo proposito, nella letteratura medica, ambientale, chimica e industriale, ricorrono con frequenza alcuni termini tecnici, che è utile conoscere per le applicazioni generali della statistica: - sensibilità (sensitivity), - specificità (specificity), - valore predittivo (predictive value), che può essere distinto in valore predittivo positivo (positive predictive value) e valore predittivo negativo (negative predictive value), - efficienza (efficiency).
Quando si applica un test biologico-chimico o si utilizza una procedura classificatoria per identificare la presenza-assenza di una sostanza specifica oppure di un attributo in un campione di più individui o oggetti, spesso è richiesto di fornire una valutazione quantitativa della capacità discriminante o selettiva del metodo. Nella sua forma più semplice e ricorrente, la riposta è espressa in termini qualitativi: il test è dichiarato positivo se la sostanza cercata è presente, negativo se è assente. Con un campione formato da più unità, la misura è una scala discreta di conteggio della presenza-assenza, tradotta poi in una proporzione sul numero totale.
Per valutare il metodo, la presenza effettiva della sostanza deve essere indicata da un’altra analisi diagnostica, condotta con criteri differenti e che viene ritenuta priva di errore. La misura della correttezza del test è fornita dalla coincidenza tra il risultato ottenuto con l’analisi di laboratorio e la realtà. L’errore che è possibile commettere è duplice: - non trovare una sostanza quando è effettivamente presente; - trovarla quando in realtà è assente. Ad esempio, per indicare la presenza di una malattia quando i sintomi non sono ancora evidenti, in medicina si ricercano precursori certi. Un indicatore è corretto quando in tutti gli ammalati è possibile ritrovare quella sostanza o attributo, che invece è sempre assente in tutti gli individui non affetti da quella malattia specifica.
Per facilitare l’esposizione didattica e la comprensione di questi concetti, si ricorre a una impostazione grafica tabellare, che permette il confronto tra la realtà e il risultato campionario di ogni singolo test.
Dalla comparazione, risulta con evidenza che sono possibili quattro esiti.
1 - Se il risultato del test è positivo e l’individuo è affetto dalla malattia, si ha un Vero Positivo (True Positive) e si parla di Sensibilità (Sensitivity) del test; 2 – Se il risultato del test è positivo mentre l’individuo non è affetto dalla malattia, si ha un Falso Positivo (False Positive); 3 – Se il risultato del test è negativo e l’individuo è affetto dalla malattia, si ha un Falso Negativo (False Negative); 4 – Se il risultato del test è negativo mentre l’individuo non è affetto dalla malattia, si ha un Vero Negativo (True Negative) e si parla di Specificità (Specificity) del test.
Con un campione formato da più individui, le frequenze dei quattro risultati possibili vengono riportati in un tabella di contingenza 2 x 2, che permette di quantificare i concetti illustrati.
Ricorrendo alla simbologia ormai abituale per indicare le frequenze assolute
TABELLA DI CONTINGENZA 2 X 2
si hanno possono ricavare i quattro indici seguenti.
1 - La sensibilità (sensitivity) di un test o una prova è - la proporzione di risultati positivi (il test indica la presenza della malattia) quando il soggetto è effettivamente ammalato:
2 – La proporzione di falsi positivi è
3 - La proporzione di falsi negativi è
4 - La specificità (specificity) di un test o una prova è - la proporzione di risultati negativi (il test non trova la malattia) quando il soggetto è effettivamente sano:
5 – La efficienza (efficiency) del test o della prova è ricavata sommando la sensibilità e la specificità in modo ponderato (cioè sia il numeratore che il denominatore):
Per l’uso corretto di questi indicatori e una loro valutazione corretta è importante rimarcare che - la sensibilità dipende solamente dalla frequenza di risultati positivi e negativi entro la popolazione di ammalati; - la specificità dipende solamente dalla distribuzione dei risultati entro la popolazione dei non ammalati.
Ne deriva che questi due indicatori - non dipendono dal rapporto tra il numero di ammalati e quello dei non ammalati - e quindi sono da considerarsi indipendenti dalla prevalenza della malattia. Sensibilità e specificità non dipendono dalla popolazione testata: sono indipendenti dalla popolazione o dal campione ai quali sono applicati e sono determinati esclusivamente dalla capacità discriminanti del test rispetto alla realtà di ogni singolo individuo.
Spesso è richiesto di valutare anche il tasso di errore, determinato dalla frequenza dei falsi positivi e dei falsi negativi. Le funzioni dei valori predittivi dei falsi positivi e dei falsi negativi, dai quali deriva la misura dell’efficienza, sono stimate mediante rapporti che considerano la popolazione complessiva, cioè l’insieme degli individui ammalati e di quelli non ammalati. Ne consegue che sono dipendenti dalla prevalenza della malattia e quindi variano da caso a caso, come la diffusione della malattia in una popolazione. La proporzione di falsi positivi, la proporzione di falsi negativi e l’efficienza del test sono indicatore della capacità del test di scoprire la malattia nella popolazione effettivamente analizzata.
ESEMPIO 1 (tratto dal testo di James E. De Muth del 1999 Basic Statistical and Pharmaceutical Statistical Application (Marcel Dekker, Inc. New York, XXI + 596 p.) Si assuma di aver sviluppato una procedura semplice, per identificare gli individui con anticorpi HIV. Ovviamente il test dovrebbe dare un risultato positivo con una probabilità molto alta, ma solo quando la persona è realmente infettata dal virus HIV (sensibilità). Una risposta errata, un falso positivo, potrebbe avere conseguenze molto gravi per l’individuo analizzato, determinando non raramente fortissimi attacchi d’ansia, in grado di condurre al suicidio. Per la verifica della sensibilità e specificità, questo test diagnostico è stato effettuato su 500 volontari, dei quali 100 indiscutibilmente affetti dalla malattia e 400 sicuramente sani.
Il risultato complessivo del test è stato
Calcolare: sensibilità, specificità, proporzione di falsi positivi, proporzione di falsi negativi, efficienza.
Risposta. 1 - La sensibilità (sensitivity) è
2 - La specificità (specificity) è
3 – La proporzione di falsi positivi è
4 - La proporzione di falsi negativi è
5 – La efficienza (efficiency) del test è
Sempre con gli stessi dati dell’esempio, è possibile ricavare altre informazioni, per la quali a volte è conveniente utilizzare non le frequenze assolute ma le loro frequenze relative:
1 – Con una sensibilità del 90% e una specificità del 98% come già stima per i dati dell’esempio, quale è la probabilità che una persona che ha gli anticorpi HIV risulti positivo al test? La stima cercata è chiamata valore positivo predetto (predicted value positive o PVP ), per il quale serve conoscere la prevalenza della malattia. Assumendo che nella popolazione la malattia abbia la stessa frequenza di quella presente nel campione di 500 volontari, quindi con una prevalenza pari a 0,20 è
Ma la proporzione 0,20 è la frequenza degli ammalati di HIV nel campione di 500 volontari. E’ la prevalenza della malattia, che in una popolazione reale quasi sempre è molto minore. Ad esempio, negli studenti dei college americani, la malattia HIV per alcuni anni ha avuto una prevalenza del 0,2% (due ogni mille studenti).
risulta uguale a 0,0827. Significa che, sebbene specificità e sensibilità appaiano elevate, vi è solamente una probabilità leggermente superiore a 8% che un individuo con gli anticorpi HIV possa essere identificato come tale con il test. Negli altri 92 casi su cento l’individuo risultato positivo al test in realtà è sano. Questo errore avviene con frequenza rilevante poiché, anche se la probabilità di un singolo errore è bassa, il numero di sani (1 - Prevalenza) è molto alto.
Secondo alcuni testi di epidemiologia, per il test HIV la specificità e la sensibilità sarebbero molto alte, pari per entrambe al 99%; ma con una prevalenza della malattia del 2 su mille si può stimare che il positive predictive value è
solamente del 16,5%. Questo fenomeno, collegato ai costi umani di un falso positivo nel caso del virus HIV, è la ragione fondamentale per cui uno screening su tutta la popolazione non è mai apparsa una idea buona. Note that now the positive predictive value is only 16,5%, meaning 5 out of very 6 positive are false positive. This phenomenon is a major reason why screening the general population for HIV infections in not a very good idea.
L’approccio statistico presentato è per analisi o test qualitativi; ma è sempre più diffuso l’uso di analisi di laboratorio che forniscono risposte quantitative. Abitualmente si è in presenza di una condizione patologica dell’individuo o dell’ambiente, quando i valori sono alti. Nella ricerca ambientale è il caso dei livelli di inquinamento; in medicina, di parametri biologici quali colesterolo, trigliceridi, glucosio e globuli bianchi nel sangue.
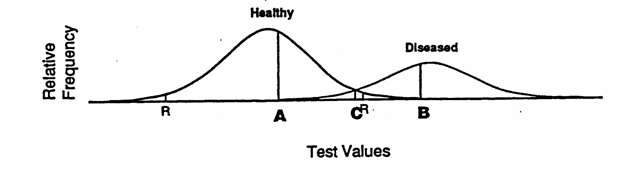
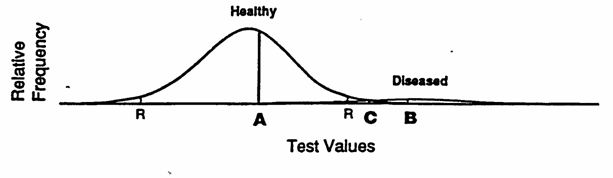
L’approccio qualitativo descritto può essere applicato anche a risultati numerici. Molti test spesso sono caratterizzati da distribuzioni di valori quantitativi che per i sani e per gli ammalati sono simili a quelli riportati nella figura. Da essi si passa a una classificazione qualitativa o binaria, mediante la selezione di un valore soglia, ritenuto biologicamente rilevante. Questo valore o punto (chiamato spesso con il termine tecnico di cutoff), è tale che tutti i valori superiori (come nel grafico) sono considerati indicazioni positive della presenza della malattia.
La scelta del valore di cutoff modifica la misura della sensibilità e della specificità del test. Ad esempio, nella figura precedente in cui la prevalenza della malattia è alta, pari al 33% della popolazione totale (come indica la proporzione dell’area occupata dalle due distribuzioni normali e quindi 66,7% sani e 33,3% ammalati), è facile osservare come scegliendo come valore discriminante o cutoff diverso si modifichino.
Con un valore di cutoff corrispondente al punteggio indicato - dal punto A, che identifica il livello sotto il quale la frequenza degli ammalati è zero, la sensibilità del test si approssima al 100% e la specificità al 60%; - scegliendo invece il punto B, sopra il quale la frequenza dei sani è nulla, la sensibilità è quasi del 60% e la specificità del 100%; - all’intersezione tra le due curve, punto C, la sensibilità è pari al 90% e la specificità al 95%; - mentre il punto R indica il punteggio di riferimento standard, in rapporto alla popolazione sana: solamente il 5% degli individui sani ha un valore superiore.
La scelta del valore di sensibilità e di specificità per test di screening della malattia dipende dai costi economici dell’analisi e dal costo etico o psicologico degli errori (inevitabili): - per malattie in cui la cura è molto efficace e il costo dell’analisi è basso, il punto di cutoff deve massimizzare la sensibilità; - per malattie a mortalità e/o morbidità alte e per le quali non esiste una cura efficace, si deve massimizzare la specificità; - in situazioni più sfumate, con malattie non gravi e una efficienza media delle cure, si deve massimizzare l’efficienza, che è identificata dall’intersezione delle due curve.
Per molte malattie, la prevalenza nella popolazione reale è bassa. Ciò non ha effetti rilevanti sulla valutazione del test.
Nella figura successiva è del 5%. Anche in questo caso, porre attenzione al fatto che le due aree devono rispettare le proporzioni tra sani e ammalati presenti nella popolazione totale:
La sensibilità e la specificità del test non cambiano, per un dato cutoff. Ne risulta invece fortemente influenzata l’efficienza, il punto di intersezione delle due curve, come pure il positive predictive value (PPV) e il negative predictive value (NPV).
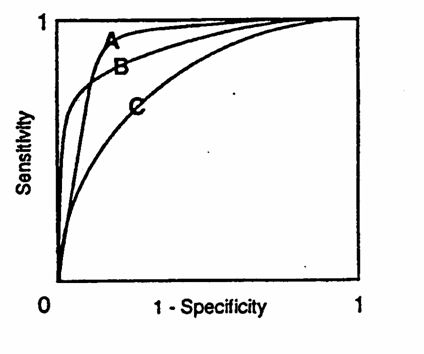
Per confrontare i livelli di sensibilità e di specificità di due o più metodi quantitativi differenti, che classificano la presenza e l’assenza della stessa malattia, si utilizzano le curve ROC. Tale termine strano nella ricerca biologica e medica (ROC = Receiver Operating Characteristic) è stato utilizzato per la prima volta per descrivere l’abilità di radio riceventi a scoprire il segnale (cioè veri positivi = sensibilità), eliminando il rumore (fasi positivi = 1- specificità). Il grafico bidimensionale riporta
il confronto tra tre curve di test, con i quali si cerca di ottimizzare la capacità di separare la popolazione in ammalati e non-ammalati. L’area maggiore sottostante alla curva ROC indica il rapporto migliore tra sensibilità e specificità. Nella figura, il test A e il test B sono entrambi chiaramente migliori del test C poiché hanno una sensibilità migliore per una data specificità. Invece la scelta tra A e B dipende dall’uso che se ne intende fare. Per ulteriori approfondimenti si rimanda alla letteratura specifica.
A conclusione dei vari concetti e metodi già illustrati e come indicazione di quelli che saranno sviluppati in capitoli successivi, è utile un elenco di statistiche derivate da una tabella 2 x 2 che sono state proposte in letteratura e di uso più frequente. Utilizzando la simbologia
e disponendo diversamente le varie informazioni, è possibile ricavare: 1 - Test
2 – Odds ratio (OR) =
3 – Relative Risk (RR) =
4 - Overall Fraction Correct =
5 – Mis-classification Rate = 1 - Overall Fraction Correct 6 – Sensitivity =
7 – Specificity =
8 – Positive Predictive Value (PPV) =
9 – Negative Predictive Value (NPV) =
10 – Difference in Proportions =
11 – Absolute Risk Reduction (ARR) =
12 – Relative Risk Reduction (RRR) =
13 – Positive Likelihood Ratio (+LR) = 14 – Negative Likelihood Ratio (-LR) = 15 – Diagnostic Odds Ratio =
16 – Error Odds Ratio =
17 – Youden’s J =
18 – Number Needed to Diagnose (NND) =
19 – Kappa di Cohen 20 – Coefficienti di contingenza, quali il Phi di Cramer, il Q di Yule e altri riportati nel capitolo relativo
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||