VERIFICA DELLE IPOTESITEST PER UN CAMPIONE SULLA TENDENZA CENTRALE CON VARIANZA NOTAE TEST SULLA VARIANZA CON INTERVALLI DI CONFIDENZA
4.22. PARAMETRI E STATISTICHE. LE PROPRIETA' OTTIMALI DI UNO STIMATORE: CORRETTEZZA, CONSISTENZA, EFFICIENZA, SUFFICIENZA. LA ROBUSTEZZA DI UN TEST
Per effettuare i test di confronto tra medie e tra varianze, la categoria più rilevante nell’inferenza statistica - è la stima dei parametri ignoti della popolazione, - quando si dispone solamente di statistiche, le misure tratte da un campione. I casi più frequenti e di maggiore utilità sono - la media del
campione - la varianza
del campione I concetti sono estensibili a ogni caratteristica della popolazione. Altri parametri frequentemenete utilizzati nella statistica univariata e bivariata sono - la frequenza relativa o proporzione in caso di fenomeni qualitativi, - il coefficiente di correlazione lineare, come indice statistico bidimensionale, quando si abbiano due fenomeni quantitativi e si intenda valutare la relazione tra essi.
Nei testi di statica teorica, l’argomento è esposto in termini più tecnici. Se - la variabile X ha una funzione di ripartizione F(x; - la cui forma dipende dal valore - è possibile stimare tale valore ( cioè
chiamata stimatore. Il valore calcolato con
è detta stima del parametro (Nella simbologia classica, con le lettere maiuscole si indicano le variabili casuali, con quelle minuscole i dati campionari di esse).
Gli stessi concetti possono essere espressi con un linguaggio ugualmente tecnico, ma meno matematico, fondato sulla teoria dell’informazione. Si dice stimatore ( Questa funzione deriva da una sintesi delle informazioni contenute
nell'insieme dei dati raccolti. Di conseguenza, allo stimatore (
E’ intuitivo che, per conoscere l’intensità di un fenomeno o il valore reale di un fattore, si debbano raccogliere più misure campionarie. Da esse si calcola un valore come può essere la media, la varianza. Si parla di un criterio di stima puntuale, in quanto si fa riferimento a un valore unico che, con i metodi della geometria può essere rappresentato come un punto sull’asse dei valori reali. Questo procedimento non è privo d’inconvenienti, quando non si può disporre di tutti i dati dell’universo. Infatti il valore sintetico del campione raccolto non coincide esattamente con il valore reale. Anzi, ne differisce di una quantità ignota. Per arrivare alla stima migliore del parametro della popolazione o universo partendo dal campione, sono state definite quattro proprietà (optimality properties), di cui uno stimatore puntuale dovrebbe sempre godere: 1 - correttezza (unbiasedness), 2 - consistenza o coerenza (consitency), 3 - efficienza (efficiency), 4 - sufficienza o esaustività (sufficiency).
1 - Si ha correttezza
o accuratezza (unbiasedness or unbiased estimator, accuracy) di uno
stimatore quando, estraendo dal medesimo universo vari campioni con lo stesso
numero di osservazioni, le singole stime risultano maggiori o minori del
valore vero (ignoto), per differenze che tendono a compensarsi.
Nell’approccio classico all’inferenza statistica, il principio del
campionamento ripetuto è fondato sulla correttezza: estraendo varie
volte un campione di Da qui la
definizione: si ha correttezza, quando la media della distribuzione delle stime
è il parametro Uno stimatore non corretto è detto distorto (biased). La differenza tra la media generale dei vari campioni e il valore (vero) del parametro della popolazione è detta distorsione nella stima o errore sistematico La misura della distorsione è
Se per
Se ciò accade solo per
lo stimatore è detto asintoticamente corretto. Tale ultimo tipo di correttezza è ritenuto una forma più blanda, in quanto realizzata solamente in condizioni teoriche o estreme. 2 - Si ha consistenza (consistency) o coerenza, quando all’aumentare del numero di osservazioni la differenza tra la stima ed il valore vero diventa minore di una quantità prefissata. In altri termini,
si ha consistenza quando il limite in probabilità dello stimatore
E’ quindi possibile scegliere un campione sufficientemente grande, che sia in grado di assicurare una differenza inferiore alla quantità prefissata. Uno stimatore consistente è anche asintoticamente corretto. Ma la consistenza non implica la correttezza per qualsiasi dimensione del campione. Questo concetto a sua volta include quello che che possono esistere più indicatori corretti, in rapporto alle varie dimensioni del campione. Affinché uno stimatore sia corretto, almeno asintoticamente, e sia contemporaneamente anche consistente, è necessario che la varianza delle stime campionarie tenda a zero, al crescere del numero di dati. La proprietà più
importante per uno stimatore è avere una varianza piccola e decrescente. Essa assicura
che, al crescere del numerosità del campione, aumenta la probabilità che la
stima campionaria
3 - Si ha efficienza o precisione (efficiency, reliability, precision) di uno stimatore, quando le varie misure sono vicine al valore reale della popolazione. Poiché spesso uno stimatore non possiede tutte e quattro le proprietà qui elencate, la scelta del migliore è fatta sulla varianza minima. Così uno stimatore è chiamato a “minimum variance” estimator. Si ha efficienza,
quando uno stimatore corretto
finita e minore di
quella di qualsiasi altro stimatore corretto Efficienza o precisione e correttezza o accuratezza sono concetti diversi e implicano metodi di valutazione differenti; ma a volte sono in concorrenza per scegliere lo stimatore migliore, che è sempre quello che maggiormente si avvicina al valore dell’universo.
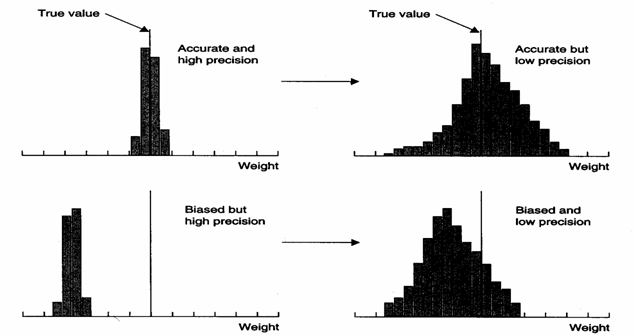
Per chiarire i concetti e illustrare i 4 differenti risultati delle loro combinazioni, molti testi usano il confronto con il tiro a un bersaglio, in cui entrano il gioco sia la precisione del tiratore sia la correttezza dello strumento. I) - Quando il tiratore è efficiente o preciso e l'arma è accurata o corretta, tutti i colpi sono sul centro del bersaglio con una rosa molto stretta. II) - Se il tiratore non è efficiente o manca di precisione, sempre sparando con un'arma accurata o corretta, i colpi finiscono distanti dal bersaglio con una rosa molto ampia; ma la media dei colpi coincide con il centro o almeno è vicina a esso. III) Se il tiratore è preciso ma l'arma non è corretta come può essere con un fucile quando il mirino è fuori allineamento tra l'occhio del tiratore e il bersaglio, i colpi finiscono molto vicini tra loro con una rosa stretta (appunto perché il tiratore sa sparare sempre sullo stesso punto), ma è collocata lontano dal centro del bersaglio. IV) Se il tiratore non è preciso e l’arma non è corretta, i colpi formano una rosa molto ampia il cui centro è distante da quello del bersaglio.
Quando si rileva una misura lineare con uno strumento, come possono essere una lunghezza con un calibro, un peso con una bilancia di precisione, la temperatura con un termometro, la concentrazione di una sostanza con un’analisi chimica si presentano le stesse 4 combinazioni tra precisione e correttezza.
4 - Si ha sufficienza (sufficiency, sufficient statistic) o esaustività, quando uno stimatore sintetizza tutte le informazioni presenti nel campione, che sono importanti per la stima del parametro. In termini più formali, questa proprietà può essere espressa mediante una distribuzione condizionale. Si ha sufficienza
per uno stimatore corretto la variabile casuale condizionata
non dipende dal
valore di Uno stimatore è considerato buono (good), - quando possiede la combinazione desiderata di correttezza (unbiasedness), efficienza (efficiency) e consistenza (consistency). Nel testo Statistics
for Experimenters del 1978, (edito da John Wiley & Sons, New York,
18 + 652 p. vedi pag. 91) gli autori George E. P. Box, William G.
Hunter, J. Stuart Hunter nel paragrafo Fisher’s concept of
sufficiency scrivono che la media Per semplicità, si
supponga di conoscere - la distribuzione
di - vale a dire che - inoltre ciò è
vero per qualsiasi altra statistica che noi scegliamo come alternativa a Ciò significa che,
una volta che
Un’altra proprietà spesso citata, ma riferita ai test, è la robustezza. Si ha robustezza (robustness, robust estimation, insensitivity) quando la distribuzione campionaria di un test non varia in maniera considerevole se una o più ipotesi sulla quale è fondato il modello teorico di distribuzione non è compiutamente rispettato. E’ una situazione che spesso si realizza nella applicazioni della statistica, come la non normalità della distribuzione degli errori e l’omogeneità della varianza di due o più gruppi. I metodi statistici che dipendono non direttamente dalla distribuzione dei valori individuali ma da quella di una o più medie tendono a essere insensitive or robust to nonnormality.
E’ noto, e sarà spesso ricordato, come il test t di Student sia robusto rispetto alla non normalità della distribuzione dei dati, specialmente quando le dimensioni del campione sono grandi, nel caso di confronto tra due gruppi le dimensioni sono uguali, almeno approssimativamente, il test è bilaterale. La robustezza è minore, nel caso di un test unilaterale, soprattutto se il livello di significatività è molto piccolo (la probabilità a < 0.01). Nel confronto tra due medie, il test t è poco robusto soprattutto quando non è rispettata la condizione di omogeneità della varianza. Questo argomento saprà approfondito nel capitolo sul test t di Student, in particolare nel paragrafo su Behrens-Fisher problem e Welch’s approximate t.
Quando - la distribuzione dei dati non è normale, - anche la
distribuzione delle medie Tuttavia, a causa degli effetti del limite centrale, - la distribuzione
di queste medie tende alla normalità all’aumentare di
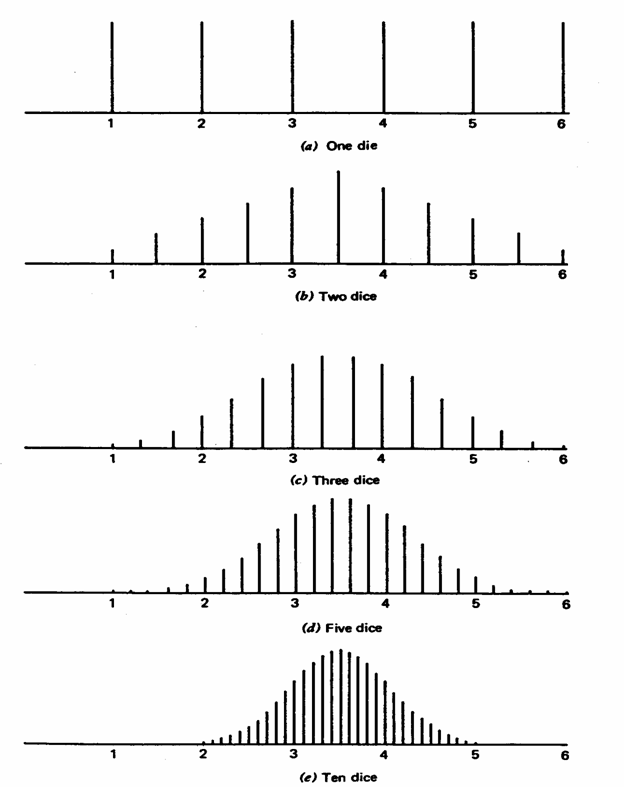
In molti testi di statistica, tale concetto è presentato didatticamnente con l’esempio di lanci ripetuti di un dado, in quanto di facile rappresentazione grafica, come nella figura riportata nella pagina successiva e già descritta nel capitolo sulle distribuzioni teoriche. - Se lanciamo un dato solo (figura a - one die), i 6 numeri escono con la stessa probabilità: - Se lanciamo due dadi (figura b - two dice) e dividiamo per due il numero ottenuto con il lancio, i valori possibili da 1 a 6 aumentano, hanno una distribuzione simmetrica e i valori centrali sono più frequenti quelli centrali. - Se il numero di dadi diventa tre (figura c - three dice) o ancor più con cinque dadi (figura d - five dice) e calcoliamo sempre le medie ottenute, i valori possibili aumentano ancora , mantenendosi sempre nei limiti di 1 e 6: La figura assume sempre più una forma normale, gli estremi diventano poco frequenti. - Con dieci dadi (figura e - ten dice), la forma della distribzuione delle medie è già perfettamente normale. In conclusione: - i numeri di ogni dado hanno una distribuzione rettangolare, quindi lontana dalla normalità; - ma le medie di k dadi hanno una distribuzione normale.
Per la varianza campionaria Se la distribuzione dei dati non è normale, - anche le varianze - e il loro valore medio
| |||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |