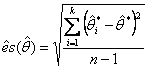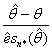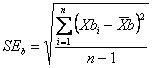|
ALTRI METODI INFERENZIALI: NORMAL SCORES E RICAMPIONAMENTO
22.6. IL BOOTSTRAP
Il Bootstrap è stato proposto da Bradley Efron nel 1979 come evoluzione del metodo jackknife, fondato sull’uso computer per stimare l’errore standard di un parametro della popolazione (vedi l’articolo Bootstrap methods: Another look at the jackknife, pubblicato su Ann. Statist. Vol. 7, pp. 1-26). In pochi anni, questa procedura ha avuto una evoluzione rapida e una serie di approfondimenti da parte dello stesso autore e dei suoi colleghi, che l’hanno resa la tecnica di ricampionamento più nota e diffusa. Una presentazione completa ed aggiornata è riportata nel volume recente e a carattere divulgativo di Bradley Efron e Robert J. Tibshirani del 1998 An Introduction to the Bootstrap, pubblicato da Chapman & Hall/CRC nella serie Monographs on Statistics and Applied Probability, vol. 57, pp. 436. Il nome bootstrap (letteralmente stringhe o lacci da scarpe), per dichiarazione dello stesso autore, è derivato dall’espressione inglese “to pull oneself up by one’s bootstrap” (tirarsi su attaccandosi ai lacci delle proprie scarpe), tratto dal romanzo del diciottesimo secolo “Adventures of Baron Munchausen di Rudolph Erich Raspe. Evidenzia, in modo scherzoso, il fatto paradossale che l’unico campione disponibile serve per generarne molti altri e per costruire la distribuzione teorica di riferimento.
Per il grande impegno scientifico e divulgativo dei suoi proponenti, il metodo bootstrap ha il vantaggio di fornire una serie ampia di esemplificazioni, in articoli pubblicati su riviste a diffusione internazionale, in merito all’inferenza anche per funzioni molto complesse. Oltre agli esempi indicati nella presentazione generale di questi metodi, sono casi ulteriori d’applicazione il calcolo dei momenti, dei coefficienti di variazione, dei rapporti tra valori medi e fra varianze, dei coefficienti di correlazione, degli autovalori delle matrici di varianze e covarianze. Altri usi nella ricerca ambientale sono l’inferenza su indici di similarità o distanza calcolati mediante la presenza-assenza di specie o mediante l’intensità di alcuni parametri fisici e chimici; la costruzione di alberi filogenetici, fondati sulle frequenze geniche o di più caratteri fenotipici.
L’uso del bootstrap non è possibile con i quantili (quanto si disponga solo di essi non dei valori reali), con dati incompleti, non indipendenti o alterati da errori grossolani. Come il jackknife,
questa tecnica permette di ricavare gli errori standard e i limiti di
confidenza di varie misure statistiche, che hanno distribuzioni non note o
molto complesse. E’ un metodo generale per ottenere informazioni circa la
variabilità e la distribuzione di statistiche campionarie Se il campione è formato da k dati, l’idea di base è di estrarre da esso per campionamento semplice con ripetizione molti campioni di k osservazioni, allo scopo di trovare la probabilità che la misura in oggetto cada all’interno di intervalli predeterminati. Il campione bootstrap è nient’altro che il campione originario nel quale, per effetto dell’estrazione con ripetizione, alcuni dati sono ripetuti ed altri, per mantenere lo stesso numero d’osservazioni, sono assenti. E’ proprio la modalità di estrazione, fondata sulla ripetizione, a generare la variabilità nelle stime; poiché è richiesto che i campioni abbiano tutti lo stesso numero d’osservazioni, se si estraesse senza ripetizione sarebbero tutti identici.
Ognuna di queste stringhe di k osservazioni può contenere due o più valori identici, con l’ovvia esclusione d’altri valori che sono contenuti nel campione originale. Sono chiamati campioni di bootstrap, ognuno dei quali permette di ottenere una stima della statistica desiderata. La distribuzione della misura statistica calcolata è trattata come una distribuzione costruita a partire da dati reali (cioè della popolazione) e fornisce una stima dell’accuratezza statistica. Per esempio, se con 15 coppie d’osservazioni è stata calcolato un r uguale a 0,782, con 10 mila stringhe è possibile stimare che il 90% (quindi con esclusione dei 500 valori minori e i 500 maggiori) variano tra 0,679 e 0,906. L’ampiezza dell’intervallo (0,227) è la misura dell’accuratezza fornita dal bootstrap, per il valore r calcolato sul campione delle 15 osservazioni raccolte. Vari autori hanno dimostrato che, molto spesso, l’ampiezza dell’intervallo stimato in questo modo corrisponde all’intervallo calcolato su campioni reali dello stesso numero d’osservazioni k. Tuttavia, come nelle misure statistiche, il risultato non è garantito: anche il bootstrap può fornire risposte fuorvianti, in una percentuale ridotta di campioni possibili, senza che sia possibile sapere in anticipo quali siano.
Per meglio comprendere i concetti in modo operativo, si possono definire i passaggi fondamentali richiesti dalla metodologia. 1 – A partire dal campione osservato (x1, x2, …, xk) chiamato dataset, ad esempio con k = 10 X1, X2, X3, X4, X5, X6, X7, X8, X9, X10 si costruisce una popolazione fittizia, ripetendo n volte ognuno dei k dati; oppure si estrae un dato alla volta, reinserendolo immediatamente, in modo che la probabilità di estrazione di ogni valore siano sempre costanti ed uguali per tutti. 2 – Si estrae un campione casuale, chiamato campione bootstrap (bootstrap sample), estraendo k dati; nella striscia possono essere presenti una o più repliche dello stesso dato e quindi mancare un numero corrispondente di valori presenti nel campione originale. Ad esempio, con k = 10, è possibile avere la striscia o campione bootstrap X1, X3, X3, X4, X5, X6, X6, X6, X7, X10 in cui sono assenti i valori X2, X8 e X9, mentre X3 è ripetuto due volte e X6 tre volte. 3 – Per ciascuno di tali campioni bootstrap si calcola lo stimatore q desiderato ottenendo una replica bootstrap (bootstrap replication). 4 – Con n estrazioni o n campioni di repliche casuali (bootstrap samples), si ottiene la successione di stime o repliche bootstrap (bootstrap replications), che sono la realizzazione della variabile casuale “stimatore bootstrap T”. 5 – La funzione di ripartizione empirica degli n valori q ottenuti fornisce una stima accurata delle caratteristiche della variabile casuale T. 6 – L’approssimazione è tanto più precisa quanto più n è elevato. 7 – Infine, dalla serie dei valori q, oltre alla media è possibile ottenere a) la stima della distorsione, b) la stima dell’errore standard, c) l’intervallo di confidenza.
A) La stima bootstrap della distorsione bk è la distanza tra il valore calcolato con i k dati originari e quello medio calcolato con le n estrazioni del metodo bootstrap. Se q è il valore calcolato con il campione osservato e
la stima bootstrap bk della distorsione è data da bk =
B) In modo analogo e con la stessa simbologia, una stima dell’errore standard della distribuzione è data da
C) L’intervallo
di confidenza può essere determinato con il metodo percentile.
Sulla base della distribuzione dei k valori Il metodo del percentile ordina per rango i valori ottenuti con le k replicazioni bootstrap, individuando i valori estremi entro i quali si collocano, 1-a (in percentuale) valori della distribuzione, con a/2 in ognuno dei due estremi. Fondato sui ranghi, il metodo ovviamente non varia anche con trasformazione dei dati. Come condizioni di validità richiede che la distribuzione bootstrap non sia distorta; nel caso di piccoli campioni, ha un’accuratezza limitata.
Il metodo del
percentile non sempre è corretto: l’intervallo di confidenza che comprende il
95% dei k valori Una stima più prudenziale, anche se valida quando i dati sono distribuiti in modo normale, è dato dall’intervallo standard z, compreso tra
considerati in valore assoluto.
Nel caso di bootstrap non parametrico, per calcolare l’intervallo di confidenza sono state proposte diversi metodi alternativi a quello del percentile (ugualmente indicativo anche in questo caso, ma con gli stessi limiti) con numerose varianti, di cui le 4 ora più diffuse sono: 1) il metodo bootstrap-t, 2) il metodo della varianza stabilizzata bootstrap-t, 3) il metodo BCa (Bias-Corrected and accelerated), 4) il metodo ABC (Approximate Bootstrap Confidence).
Il metodo bootstrap-t e il metodo della varianza stabilizzata bootstrap-t (the variance-stabilized bootstrap-t) hanno in comune l’idea di correggere la distribuzione ottenuta mediante la distribuzione z o la distribuzione t. Come già visto nel caso delle medie, sono da applicare soprattutto quando il campione è di piccole dimensioni. L’intervallo è compreso tra
E’ importante ricordare che i due metodi t non necessariamente utilizzano la distribuzione t di Student, ma una distribuzione ottenuta con una seconda serie di valori “bootstrappati” derivati da t* = che può coincidere
con la distribuzione t di Student solo quando q = m e In generale, se
l’errore standard della statistica campionaria 1) dopo una parte iniziale identica a quella precedente, a)
dalla
popolazione fittizia di n repliche dei k dati campionari,
estrarre un campione di k dati e calcolare b)
generare
una intera striscia con n
2)
generare
una serie di queste stime a)
dalla
quale calcolare b)
ripetere
queste ultime operazioni in modo da ottenere c)
calcolare
la deviazione standard di questi d) calcolare t* =
3) ripetere l’operazione per ottenere t1*, t2*, …, tn*;
4) dalla distribuzione di questi valori, utilizzando i percentili ta/2*e t1-a/2* si ottiene l’intervallo di confidenza per q, che alla probabilità a sarà compresa nell’intervallo tra
preso in valore assoluto.
Questo metodo è generalmente valido per stimare parametri di posizione (come la mediana), in modo particolare se si ricorre al bootstrap parametrico; ma non è ugualmente attendibile nella stima di altri parametri, specialmente quando i campioni sono piccoli- Il metodo variance-stabilized bootstrap-t corregge il metodo bootstrap –t precedente.
Il metodo BC (Bias-Corrected) indicato ora più frequentemente BCa (Bias-Corrected and accelerated) è un altro miglioramento del metodo percentile, da utilizzare soprattutto nel caso di bootstrap non parametrico: “centra” la distribuzione del bootstrap sul valore del parametro calcolato con i dati del campione osservato e per essa stima i quantili asintotici. Non tiene conto della eventuale asimmetria ed implica un’assunzione parametrica, come avviene per la distribuzione normale e la distribuzione t. Secondo Efron determina un miglioramento sostanziale rispetto ai metodi precedenti, fornendo una stima “good” dell’intervallo di confidenza; la stima è giudicata buona quando i calcoli effettuati con il computer stimano intervalli di confidenza molto vicini a quelli forniti come probabilità esatta dalla teoria.
Il metodo ABC (Approximate Bootstrap Confidence) usa alcuni risultati analitici, per ridurre il numero di campioni bootstrap necessari nel metodo Bca. E’ quindi una evoluzione del metodo precedente, ma finalizzata solamente ad effettuare meno calcoli: non fornisce risposte migliori.
ESEMPIO 1. Un esempio semplice di calcolo dell’accuratezza della stima di una differenza può essere tratto dal volume di Efron e Tibshirani citato. Dati due campioni indipendenti (A e B), il primo con 7 misure e il secondo con 9 riportate nella tabella (ordinate per rango, in modo da facilitare l’individuazione della mediana, la variabilità e la tendenziale forma di distribuzione dei dati)
è possibile stimare la media, il suo errore standard e la mediana - del gruppo A: media = 86,86; es = 25,24; mediana = 94 - del gruppo B: media = 56,22; es = 14,14; mediana = 46 - della differenza (A-B): media = 30,63; es = 28,93; mediana = 48 dove l’errore standard della differenza è
Successivamente, - dopo
l’estrazione casuale con repliche di 7 dati dal gruppo A e di 9 dati dal gruppo
B, si ottiene un campione bootstrap di cui si stimano le rispettive due
medie e la differenza tra loro (una replica bootstrap), indicata con - ripetendo l’operazione n volte (n campioni bootstrap), si ottengono n stime della differenza tra le due medie (n repliche bootstrap). - Di queste n
stime o n repliche bootstrap si calcola la media generale, indicata con L’errore standard della stima bootstrap (SEb) è la deviazione standard calcolata sugli scarti di ogni replica bootstrap (che è una media) dalla loro media generale di n repliche
Nell’esempio di Efron, la stima errore standard (SEb) oscilla al variare di n verso il valore asintotico
Come è stato fatto per la media, è possibile per ogni parametro, anche se cambia la formula per la stima del parametro di tutta la distribuzione e quella del suo errore standard. Ad esempio, per la mediana si calcola tale valore per ogni campione bootstrap, ottenendo n repliche bootstrap della mediana. Da questa distribuzione si stima la mediana generale e, con formula più complessa ma sulla base dello stesso principio, si stima il suo errore standard. Nel testo di Efron e Tibshirani, risulta
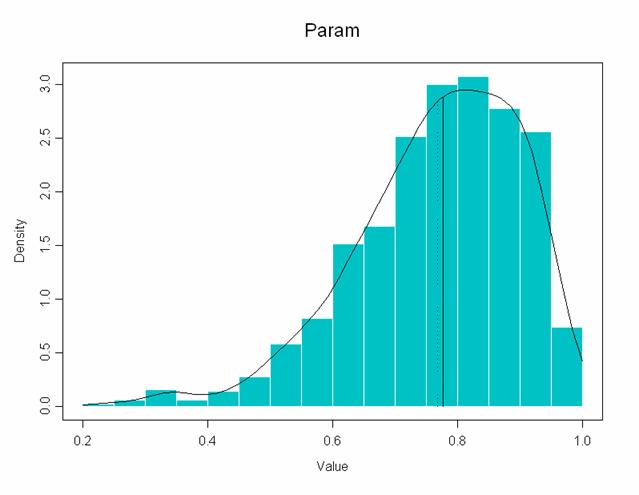
ESEMPIO 2. Con il metodo bootstrap calcolare il coefficiente di correlazione e il suo errore standard, utilizzando gli stessi dati utilizzati dell’esempio con il metodo jackknife. Dopo l’estrazione di un campione bootstrap di 15 dati e la stima di r, con 1000 repliche bootstrap il computer ha fornito i risultati rappresentati nel grafico seguente
Insieme con il grafico, i programmi informatici riportano le statistiche relative.
Summary Statistics:
Empirical Percentiles:
BCa Percentiles:
Una illustrazione discorsiva della loro lettura può essere presentata in alcuni punti. a) Il valore di r calcolato sui 15 dati osservati è r = 0.7764 (ovviamente la risposta è uguale a quella data dal programma per il metodo jackknife). b) La media delle 1000 repliche campionarie (n = 1000) ottenute per estrazione casuale di 15 numeri è uguale a r = 0,7676 e il suo errore standard è SE = 0,1322 .Sono leggermente diversi dalla stima jackknife che risultavano rispettivamente r = 0,7759 e SE = 0,1425. Poiché l’errore standard è minore, Efron conclude che la stima bootstrap è più accurata. c) Anche un nuovo calcolo bootstrap, fondato sull’estrazione casuale, non darebbe risultati esattamente coincidenti, anche se sempre più simili all’aumentare del numero n delle repliche. d) Il bias, la differenza tra la stima di r con i 15 dati campionari e stima della media degli r ottenuti con il metodo bootstrap, è bias = –0,0088. In questo caso risulta maggiore di quello ottenuto con il metodo jackknife, dove risultava bias = -0,0005. Ma questa non è una indicazione della maggiore precisione di quel metodo, trattandosi di uno scarto da un valore campionario, stimato su soli 15 dati. e) Quando il campione è piccolo, un aumento del numero di ricampionamenti non determina un miglioramento reale, poiché i cambiamenti sono piccoli rispetto alla deviazione standard. f) Le due strisce precedenti danno le stime dell’intervallo di variazione, con il metodo dei percentili empirici e quella dei percentili BCa.
Il jackknife ed il bootstrap rientrano nell’area dei metodi statistici chiamata data analysis, insieme con i test di casualizzazione, con alcune tecniche di rappresentazione grafica (che mostrano le caratteristiche di una distribuzione e gli effetti delle trasformazioni) e con la cross-validation, che consiste nel dividere casualmente i campioni in due parti uguali per eseguire alcune analisi alternative (come una regressione con numero differente di parametri alla quale sono applicate trasformazioni differenti), finché con il secondo campione si ottiene una risposta simile a quella del primo). Definita come la ricerca sistematica e approfondita di una serie di dati per evidenziarne le informazioni e le relazioni, rappresenta la parte nuova della statistica applicata alla ricerca biologica ed ambientale. Per alcuni autori, è anche quella parte della statistica che promette gli sviluppi più interessanti, per i prossimi anni.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||