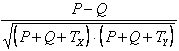|
TEST NON PARAMETRICI PER CORRELAZIONE, CONCORDANZA, REGRESSIONE MONOTONICA E REGRESSIONE LINEARE
21.2. IL COEFFICIENTE DI CORRELAZIONE t (tau) DI KENDALL; IL ta E tb DI KENDALL CON I TIES.
Oltre 30 anni dopo il r (o rs) di Spearman, - M. G. Kendall nel 1938 con l’articolo A new measure of rank correlation (pubblicato su Biometrika vol. 30, pp. 81-93) e in modo più dettagliato nel 1948 con la descrizione dettagliata della metodologia nel volume Rank correlation methods (edito a Londra da C. Griffin) ha proposto il test
- ha le stesse assunzioni, - può essere utilizzato nelle medesime condizioni e - sui medesimi
dati del test
I risultati tra
i due test sono molto simili, anche se matematicamente non equivalenti, per
i motivi che saranno di seguito spiegati con l’illustrazione della metodologia.
Tuttavia, da parte di molti autori il Il vantaggio del
test - sia all'analisi dei coefficienti di correlazione parziale o netta (illustrata nei paragrafi successivi), che tuttavia successivamente è stata estesa anche al r con risultati equivalenti, - sia alla misura dell’accordo tra giudizi multipli.
La metodologia per stimare il t di Kendall può essere suddivisa in 6 fasi: le prime due sono uguali a quelle del test r di Spearman, si differenzia per la misura dell’accordo tra le due distribuzioni.
1 - Dopo la presentazione tabellare dei dati con due misure per ogni oggetto d’osservazione
occorre ordinare per ranghi la variabile X, assegnando il rango 1 al valore più piccolo e progressivamente un rango maggiore, fino ad N, al valore più grande. Se sono presenti due o più valori uguali nella variabile X, assegnare ad ognuno come rango la media delle loro posizioni. La scala comunque dovrebbe essere continua, anche se di rango, e quindi non avere valore identici, se non in casi eccezionali.
E' indispensabile collocare nell'ordine naturale (da 1 a N) i ranghi della variabile X, spostando di conseguenza i valori della Y relativi agli stessi soggetti
2 - Sostituire gli N valori di Y con i ranghi rispettivi; per valori di Y uguali, come al solito usare la media dei ranghi.
I ranghi di Y risultano distribuiti secondo il rango della variabile X, come nella tabella seguente:
Il metodo proposto da Kendall utilizza le informazioni fornite dall’ordine della sola variabile Y. E’ un concetto che richiama il metodo delle precedenze, già utilizzate in vari test nn parametrici per il confronto tra le tendenze centrali.
3 - Se le due distribuzioni sono correlate - in modo positivo (r = +1), anche i ranghi della variabile Y sono ordinati in modo crescente, concordanti con l'ordine naturale; - in modo negativo (r = -1), i valori di Y risulteranno ordinati in modo decrescente e saranno discordanti dall'ordine naturale; - se tra le due variabili non esiste correlazione (r = 0), l'ordine della variabile Y risulterà casuale e il numero di ranghi concordanti e di quelli discordanti dall'ordine naturale tenderà ad essere uguale, con somma 0.
Per quantificare il grado di correlazione o concordanza, Kendall ha proposto di contare per la sola variabile Y
- quante sono le coppie di ranghi che sono concordanti e - quante quelle discordanti dall'ordine naturale.
Per esempio, elencando in modo dettagliato tutte le singole operazioni, - il valore 2 è seguito da 1: non è nell’ordine naturale e pertanto contribuirà con -1; inoltre è seguito da altri 5 valori maggiori, che contribuiranno insieme con +5: il contributo complessivo del valore 2 al calcolo delle concordanze è uguale a +4; - il valore 1 è seguito da 5 valori maggiori e contribuirà con + 5; - il valore 4 contribuisce con -1, perché seguito dal 3, e con +3, in quanto i 3 successivi sono maggiori, per un valore complessivo di +2; - il valore 3 contribuisce con +3; - il valore 7 contribuisce con -2, in quanto seguito da 2 valori minori; - il valore 5 contribuisce con +1. - il valore 6 è l’ultimo e non fornisce alcun contributo al calcolo delle concordanze; con esso termina il calcolo delle differenze tra concordanze e discordanze.
Nella tabella seguente è riportato il conteggio dettagliato e complessivo delle concordanze (+) e delle discordanze (-)
La misura della concordanza complessiva con la variabile X è dato dalla somma algebrica di tutte le concordanze e le discordanze. Il totale di concordanze e discordanze dei 7 valori dell’esempio (+4, +5, +2, +3, -2, +1) è uguale a +13.
4 – Per ricondurre il valore calcolato a un campo di variazione compreso tra +1 e –1, il numero totale di concordanze e discordanze di una serie di valori deve essere rapportato al massimo totale possibile. Poiché i confronti sono fatti a coppie, con N dati il numero totale di confronti concordanti o discordanti è dato dalla combinazione di N elementi 2 a 2
Con una serie di 7 dati come nell’esempio, il numero complessivo di confronti, quindi il massimo totale possibile di concordanze o discordanze, è
uguale a 21.
5 - Secondo il
metodo proposto di Kendall, il grado di relazione o concordanza (
Con i 7 dati dell’esempio,
t è uguale a +0,619.
Il - +1, quando la correlazione tra X e Y è massima e positiva, - -1, quando la correlazione tra le due variabili è massima e negativa; - 0, quando non esiste alcuna correlazione.
La formula abbreviata è
dove N è il numero di coppie di dati.
Nel caso in cui
siano presenti due o più valori identici nella successione delle Y, il
confronto con l’ordine naturale non determina né una concordanza né una
discordanza: il loro confronto non contribuisce al calcolo di La mancata correzione comporterebbe che il rango di variazione non sarebbe più tra -1 e +1.
Considerando la presenza di valori identici sia nella variabile Y sia nella variabile X, la formula corretta diventa
dove - N è il numero totale di coppie di dati delle variabili X e Y, - - - -
Nel caso di ties, da L. A. Goodman e W. H. Kruskal nel 1963 (vedi l’articolo Measures of association for cross-classifications. III: Approximate sample theory, pubblicato su Journal of the American Statistical Association Vol. 58, pp. 310 – 364) hanno proposto che t sia stimato con la relazione
dove - NC = numero di concordanze - ND = numero di discordanze
Questo valore t è strettamente correlato con il coefficiente gamma (gamma coefficient), tanto da poter essere identificato con esso, come sarà dimostrato nel paragrafo dedicato a tale indice; ha il grande vantaggio di variare tra +1 e –1 anche quando sono presenti dei ties.
Valori critici del coefficiente di correlazione semplice t di Kendall per test a 1 coda e a 2 code a
Per piccoli campioni, i valori critici sono forniti dalla tabella relativa, riportata nella pagina precedente. Il risultato dell’esempio, con N = 7, per un test ad 1 coda risulta significativo alla probabilità a =0.05.
Per grandi
campioni la significatività del con la distribuzione normale Z
Quando è vera l'ipotesi nulla (assenza di correlazione o d’associazione), - per la media
(cioè l'ordine della variabile Y è casuale e la somma totale delle sue concordanze e discordanze è nulla),
- mentre la
varianza
dove N è il numero di coppie di dati.
Sostituendo nella precedente relazione(*) per la normale Z e semplificando, con la formula abbreviata si ottiene - una stima più rapida di Z mediante la relazione
Anche in questo caso sono stati proposti altri metodi per valutare la significatività di t. Tra i testi a maggior diffusione, quello di - W. J. Conover del 1999 (Practical nonparametric statistics, 3rd ed. John Wiley & Soons, New York, 584) riporta i valori critici dei quantili, esatti quando X e Y sono indipendenti, - proposti da D. J. Best nel 1973 (nell’articolo Extended tables for Kendall’s tau, pubblicato su Biometrika Vol. 60, pp. 429-430) e nel 1974 (nella relazione Tables for Kendall’s tau and an examination of the normal approximation, pubblicato su Division of Mathematical Statistics, Technical Paper n° 39, edito da Commonwealth Scientific and Industrial Research Organization, Australia)
ESEMPIO. Mediante
il
La metodologia del 1 - ordinare in modo crescente i valori del BOD5 ed attribuire i ranghi relativi; 2 - trasformare in ranghi i corrispondenti valori di N; 3 - calcolare per ogni punteggio di N il numero di concordanze e di discordanze; 4 - calcolare la somma complessiva di tutte le concordanze e le discordanze.
La somma totale delle differenze tra concordanze e discordanze risulta positiva (+63).
5 - Tradotto nel corrispondente coefficiente mediante
si ottiene un
valore di
6 - Per un test
unilaterale, la tabella dei valori critici del - con N = 16 e alla probabilità a = 0.005 - riporta un
valore di Il valore calcolato (0,525) è superiore in modulo.
Di conseguenza, si rifiuta l'ipotesi nulla e si accetta l'ipotesi alternativa: esiste un’associazione o correlazione positiva tra le due serie di dati, con probabilità P < 0.005 di commettere un errore di I tipo.
Il campione utilizzato nell’esempio può essere ritenuto sufficientemente grande. Pertanto, è
possibile valutare la significatività del coefficiente mediante il test Z:
che risulta Z = +2,93. Nella distribuzione normale, a Z uguale a 2,93 per un test ad una coda corrisponde una probabilità P = 0,0017. E’ un risultato che non si discosta in modo rilevante da quello precedente, fornita dalle tabelle dei valori critici.
Alcuni testi di statistica presentano una procedura di calcolo delle precedenze che è più complessa di quella illustrata e propongono 2 misure differenti (ta, tb); la scelta tra ta e tb dipende dal numero di valori identici e quindi dalla continuità del tipo di scala utilizzato. E’ possibile determinare i casi concordi, discordi oppure a pari merito, confrontando simultaneamente i valori di X e Y in una coppia d’oggetti.
Una coppia di casi è - concorde (P), se per un oggetto i valori di entrambi le variabili sono più bassi o più alti rispetto ai valori dell’altro caso; - discorde (Q), se per una variabile è maggiore e per l’altra minore, o viceversa; - pari merito (T), se hanno lo stesso valore per la variabile X (TX) o per la variabile Y (TY).
Il ta è la differenza tra coppie concordi e discordi (P-Q), rapportata al numero totale di coppie d’oggetti: ta =
Se non esistono coppie con valori uguali, questa misura varia tra -1 e +1. Se esistono coppie con valori uguali, il campo di variazione è più limitato e dipende dal numero di valori pari merito presenti sia nella variabile X che nella variabile Y.
Il tb normalizza la differenza P-Q, prendendo in considerazione anche i valori pari merito delle due variabili in modo separato tb =
L’associazione tra due variabili può essere valutate anche con altri metodi, che utilizzano tabelle di contingenza.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||