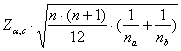|
TEST NON PARAMETRICI PER PIU' CAMPIONI
15.5. CONFRONTO CON IL TEST F E Confronti multipli CON I RANGHI.
Secondo alcuni autori di testi di Statistica non parametrica, tra i quali G. Landenna e D. Marasini, (vedi Metodi statistici non parametrici, edito da il Mulino, Bologna, 1990, pag. 234) “un diverso modo per verificare l’ipotesi nulla H0: meA = meB = … = meK, in alternativa all’ipotesi H1 in cui non tutte le mediane sono uguali, è quello di ricorrere ai confronti multipli che, nel caso di rifiuto dell’ipotesi nulla, consentono anche la identificazione delle popolazioni con mediane diverse ovvero dei trattamenti i cui effetti hanno provocato il rifiuto medesimo”. A parere della maggioranza degli autori, questo concetto non è espresso con la dovuta chiarezza e può indurre in errore. Anche nella statistica non parametrica per k campioni, - è possibile ricorrere ai confronti multipli, per individuare quali sono i gruppi che hanno una tendenza centrale tra loro significativamente differente, - solo se è stata rifiuta l’ipotesi nulla con il test di Kruskal-Wallis (più avanti si vedrà anche il test di Jonchkeere e il test Umbrella di Mack-Wolfe). E’ un principio di cautela, al quale molti testi consigliano di attenersi. Il motivo è che le due risposte potrebbero non coincidere, date le differenze esistenti tra i vari metodi e la stima non coincidente della probabilità experiment-wise rispetto a quella dei comparison-wise. Quindi anche con il test di Kruskal-Wallis si potrebbe non rifiutare l’ipotesi nulla, quando i confronti multipli evidenziano almeno una differenza significativa.
Nel caso di confronti multipli non parametrici, una procedura molto lunga, possibile solo con programmi informatici ma concettualmente molto semplice, è fondata sugli stessi principi del test di casualizzazione (o permutation test), già illustrato sia per due campioni dipendenti che indipendenti. Con N dati suddivisi in k gruppi, è teoricamente facile - analizzare tutte le possibili risposte, determinate dalle diverse collocazioni dei valori nei k gruppi; -
stabilire
la probabilità a con l’applicazione del principio del Bonferroni: il valore della
probabilità a
di ogni confronto è ottenuto dividendo la probabilità totale per il numero di
confronti possibili. Ad esempio, scegliendo la probabilità complessiva di aT = 0.05, per ognuno
dei k confronti il valore di
- sono collocati nella zona di rifiuto dell’ipotesi nulla le distribuzioni dei ranghi che danno le differenze massime tra i ranghi secondo questa nuova probabilità. La probabilità utilizzata per ogni confronto è così bassa da impedire di superare quella experiment-wise prefissata. Ma, appunto per questo, sono test poco potenti.
Metodi operativi concettualmente più complessi, ma operativamente più rapidi, sono quelli analoghi alle procedure presentate nei confronti multipli. Secondo la logica già esposta nella presentazione del t di Bonferroni, il valore della probabilità deve essere diviso per il numero di confronti possibili. Ad esempio, con campioni abbastanza grandi è possibile - scegliere la probabilità complessiva di a = 0.05; -
successivamente,
per effettuare tutti i confronti tra k gruppi, occorre utilizzare il
valore di Z (o di t quando i campioni sono molto piccoli)
corrispondente ad un valore di
Per evitare di effettuare tutti i possibili confronti tra coppie di medie con k gruppi (pari a Ck2), - con una procedura analoga a quella del test parametrico T di Tukey, -
si
calcolano le differenze in valore assoluto
Di esse sono
significative, alla probabilità D = dove - N è il numero complessivo di dati considerando tutti i gruppi, - na e nb sono il numero di dati nei due gruppi (chiamati a e b) a confronto, - c è il numero di possibili confronti, che con k
gruppi e uguale a - Z alla probabilità a/c è tratta dalla distribuzione normale.
Se i gruppi a confronto hanno tutti lo stesso numero d’osservazioni, è corretto e conveniente calcolare un solo valore (D), chiamato differenza minima significativa (least significant difference). Sono significative tutte le differenze tra coppie di medie di ranghi che risultano superiori alla quantità D calcolata.
ESEMPIO. In alcuni tratti di 5 corsi d'acqua è stata misurata la quantità di tensioattivi anionici (misurata in mgl-1) presenti
Dopo aver verificato se esistono differenze significative tra le mediane dei diversi corsi d'acqua, in caso positivo, individuare tra quali corsi tali differenze sono significative.
Risposta. I primi passi dell'analisi sono: - trasformare i valori nei loro ranghi, - annotare quanti sono i valori identici e quante le loro repliche.
E' inoltre utile ricordare che, quando sono presenti valori identici, il rango da attribuire è il loro valore medio. Con un numero elevato di gruppi e di osservazioni entro ogni gruppo è facile incorrere in errori nell'attribuzione dei ranghi. Una verifica rapida dei calcoli è data dalla corrispondenza tra somma totale dei ranghi e numero totale di osservazioni: tra essi esiste l’uguaglianza Somma di tutti i
ranghi Nell’esempio, l’operazione di attribuzione dei ranghi e le loro somme per gruppo sono state effettuate in modo corretto, poiché,
Per il calcolo di g è utile ricordare che k = 5 e N = 33; pertanto si ottiene un valore
di g uguale a 21,704. Con 5 gruppi, la
significatività è fornita dalla tabella sinottica dei valori critici del - alla probabilità a = 0.05 è uguale a 9,49, - alla probabilità a = 0.01 è uguale a 13,28, - alla probabilità a = 0.001 è uguale a 20,52.
A causa della presenza di misure ripetute, può rivelarsi vantaggioso correggere il valore di g (non in questo caso, in quanto già significativo ad una probabilità inferiore a 0.001). Con i dati dell'esempio, poiché sono presenti i seguenti valori identici riportati nella tabella:
il fattore di correzione C è
uguale a 0,996658. Il valore corretto di g diventa
uguale a 21,777 che, ovviamente, è ancor più significativo del valore stimato in precedenza.
Rifiutata l'ipotesi nulla (tutti i gruppi o campioni siano estratti dalla stessa popolazione o da popolazioni con la medesima mediana) e quindi accettata l'ipotesi alternativa (non tutte le mediane dei gruppi a confronto sono uguali), si può mettere in evidenza quali sono le medie dei ranghi che hanno una differenza significativa. Per confronti semplici tra tutte le medie dei ranghi, con 5 campioni il numero di differenze può essere stimato con
e risulta uguale a 10. Esse possono essere riportate in valore assoluto in una matrice triangolare con il relativo numero di osservazioni
Alla probabilità complessiva aT = 0.05 per 10 confronti simultanei, la probabilità a di ogni confronto è uguale a 0.005; per un test bilaterale (quindi alla probabilità a = 0.0025 in una coda della distribuzione) sulla tavola della distribuzione normale ad essa corrisponde un valore di Z uguale a 2,81 (esattamente 2,807).
Per un test a due code, la differenza minima significativa D (con N = 33) per il confronto tra A e B che hanno entrambe 6 osservazioni
è uguale a 15,66. Per i 6 confronti tra le medie dei ranghi dei campioni A e B, che hanno 6 osservazioni, con i campioni C, D e E che hanno 7 osservazioni,
Per i 3 confronti tra i gruppi C, D e E che hanno 7 osservazioni,
Confrontando i
valori - la differenza tra la media dei ranghi del gruppo A e quella del gruppo E, - la differenza tra la media dei ranghi del gruppo B e quella del gruppo E, - la differenza tra la media dei ranghi del gruppo C e quella del gruppo E.
Osservando i tre diversi intervalli calcolati (15,66 - 15,10 - 14,51) è didatticamente utile sottolineare come l'intervallo diminuisca in modo non trascurabile anche all'aumento di una sola osservazione, quando i campioni sono numericamente così ridotti. Con lo stesso numero di gruppi, l'intervallo minimo significativo varia anche in rapporto al numero di confronti che si vogliono fare. Se, in modo analogo al test di Scheffé, si intende effettuare oltre ai confronti semplici anche confronti complessi tra le medie combinate di alcuni gruppi, il valore di Z cambia (cresce in rapporto all'aumentare del numero totale di confronti possibili, come evidenziato dalla tabella relativa). Ad esempio, se si intendono fare 15 confronti - mantenendo costante la probabilità complessiva di aT = 0.05, - la probabilità a di ogni confronto diventa (0.05/15) uguale a 0.0033 per un test unilaterale - e a 0.00167 per un test bilaterale, al quale corrisponde un valore di Z uguale a 2,94.
Nel caso di confronti tra alcuni trattamenti ed un controllo (per esempio, se si intendesse confrontare le medie dei trattamenti B, C, D, E solamente con la media del campione A, ritenuto la situazione normale o standard) il numero di confronti si riduce notevolmente; è pari a k-1, quando k è il numero totale di gruppi. Il metodo è utilizzato in medicina quando si intendono valutare gli effetti di alcuni farmaci rispetto al solo placebo; è frequente nella ricerca tossicologica ed ambientale, per confrontare più situazioni a rischio con quella normale. Con 5 gruppi o campioni, di cui 1 è il placebo o controllo e 4 sono i farmaci o le situazioni da verificare, il numero di confronti è 4. Dopo aver applicato l'analisi della varianza di Kruskal-Wallis per dimostrare l'esistenza di almeno una eventuale differenza tra i 5 gruppi, è possibile verificare la significatività di ognuna delle differenze tra le mediane dei k-1 trattamenti rispetto alla mediana o tendenza centrale del controllo.
Il procedimento è identico al precedente, con 2 sole variazioni:
1 - Alla medesima probabilità di rifiutare l'ipotesi nulla, il valore di Z è minore, perché inferiore è il numero di possibili confronti; di conseguenza, sarà minore anche il valore della differenza minima significativa, a parità del numero di osservazioni impiegate nei rispettivi gruppi. Per esempio alla probabilità complessiva aT = 0.05 la probabilità a di ogni confronto diviene: - 0.05/4 uguale a 0.0125 e il valore di Z corrispondente è uguale a 2,24 per un test ad una coda, - 0.025/4 uguale a 0.00625 e il valore di Z corrispondente è uguale a 2,50 per un test bilaterale.
2 - Con lo stesso numero N di osservazioni totali, è possibile ottenere una maggiore efficienza - potenza dei 4 confronti, non programmando gruppi con lo stesso numero di dati ma ponendo un maggiore numero di osservazioni nel gruppo o campione di controllo. Infatti, il suo numero di osservazioni viene utilizzato nei calcoli di tutte le k-1 differenze minime significative. Ad esempio, con 30 osservazioni e 5 gruppi invece di attribuire 6 dati per gruppo risulta più conveniente assegnare 5 osservazioni ai 4 trattamenti e 10 osservazioni al controllo. I 4 confronti saranno tutti tra due gruppi rispettivamente di 10 (il controllo) e 5 (un trattamento) osservazioni; essi risultano più potenti di 4 confronti effettuati sempre tra due gruppi di 6 osservazioni (sia il controllo che un trattamento).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |