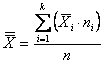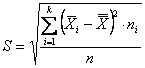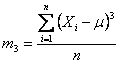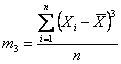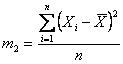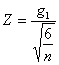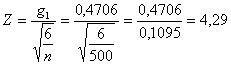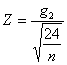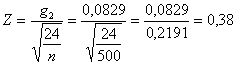|
trasformazionI dei dati; test per normalita’ e PER OUTLIER
13.6. TEST PER LA VERIFICA DI NORMALITA’, SIMMETRIA E CURTOSI, CON I METODI PROPOSTI DA SNEDECOR-COCHRAN
Prima e dopo la trasformazione dei dati, occorre misurare e verificare le caratteristiche fondamentali della loro distribuzione, per verificare se esiste normalità, simmetria , curtosi. Il confronto di queste due serie di indici, quelli prima della trasformazione e quelli dopo, permette di valutarne l’effetto. Inoltre, la scelta del test, soprattutto se parametrico o non parametrico, dipende in larga misura da queste risposte. I metodi proposti in letteratura sono numerosi. Disponendo di una distribuzione di frequenza, è possibile ricorrere a tre test differenti per verificare: - la normalità (normality), - la simmetria (skewness), - la curtosi (kurtosis).
Tra essi, per campioni sufficientemente grandi, possono essere ricordati quelli proposti da George W. Snedecor e William G. Cochran nel loro testo (Statistical Methods, 6th ed. The Iowa State University Press, Ames Iowa, U.S.A.). Nelle varie ristampe, dalla metà del Novecento e per oltre un trentennio è stato uno dei testi di riferimento più importanti per gli studiosi di statistica applicata. I metodi da essi proposti e qui ripresi sono parte della impostazione classica, che è bene conoscere anche quando gli attuali programmi informatici ricorrono a procedure differenti, ritenute più potenti o più precise.
Per valutare la normalità di una distribuzione di dati sperimentali Snedecor e Cochran propongono di ricorre al test c2, chiamato appunto test per la bontà dell’adattamento (goodness of fit test), confrontando - la distribuzione osservata - con quella attesa, costruita mediante la media e la varianza del campione applicate alla normale. L’ipotesi nulla è che non esistano differenze significative tra la distribuzione dei dati raccolti e quella normale corrispondente, con stessa media e stessa varianza. L’ipotesi alternativa è che la distribuzione osservata se ne discosti in modo significativo, per un effetto combinato di asimmetria e curtosi. Per presentare in modo dettagliato la procedura di verifica, si supponga di avere raccolto 500 misure di una scala continua e che la loro distribuzione di frequenza sia quella riportata nelle prime due colonne della tabella seguente.
Partendo dai dati campionari, è necessario: - stimare le frequenze attese (riportate nella terza colonna), - calcolare il valore del c2, con i seguenti passaggi logici.
1 – Si individuano
i valori centrali (
2 - Si calcola la media
generale ( con
dove - - -
3 – Si calcola la deviazione standard ( con
4 – Si stima il
valore di Z per gli estremi di ogni classe ( la relazione
5 – Dal valore Z di ogni estremo di classe si ricava, attraverso la tavola della distribuzione normale, la frequenza relativa corrispondente (già illustrato negli esempi del primo capitolo); per differenza, si stima la frequenza relativa di ogni classe.
6 – Rapportando a
7 – Per ogni classe si stima il c2, mediante la formula classica
8 – Poiché è condizione di validità di questo test che ogni frequenza attesa non sia inferiore a 5, nel caso dell’esempio le ultime tre classi devono essere raggruppate in una sola, riducendo così il numero totale di classi da 13 a 11.
9 – La somma degli 11 valori c2 fornisce il valore del c2 totale (uguale a 27,63), che ha 8 gdl.
10 – Infatti, benché esso sia stato ottenuto dalla somma di 11 valori, la distribuzione attesa è stata calcolata sulla base di tre quantità ricavate da quella osservata: la media, la deviazione standard e il numero totale di osservazioni. Di conseguenza, i gdl di questo c2 sono 11-3 = 8.
11 – Il valore critico per 8 gdl alla probabilità a = 0.005 è c2 = 21,96. Poiché il valore calcolato (27,63) è superiore a quello critico, si rifiuta l’ipotesi nulla alla probabilità specificata: la distribuzione osservata è significativamente differente da una distribuzione normale, che abbia la stessa media e la stessa varianza.
Già il semplice confronto tabellare tra la distribuzione osservata e quella attesa evidenziava alcune differenze: ma il test permette di valutare tale scostamento in modo oggettivo. Il chi quadrato per la normalità è un test generalista: somma gli effetti di tutti gli scostamenti dalla normalità e non è diretto ad evidenziare gli effetti di una causa specifica. Nei dati della tabella precedente, appare evidente che la distribuzione osservata è asimmetrica; ma occorre essere in grado di fornirne un indice numerico e valutarne la significatività con test specifici.
Il test per la skewness (termine introdotto da Karl Pearson nel 1985, con la funzione b) di una popolazione di dati è fondato sul valore medio della quantità
dove X è ogni singolo valore e m è la media della popolazione. La misura fondamentale della skewness, in una popolazione di n dati, è indicata con m3
e è chiamata momento terzo intorno alla media (third moment about the mean) o momento di terzo ordine. Il suo valore - è uguale a 0 (zero) quando la distribuzione dei dati è perfettamente simmetrica, - è positivo quando la distribuzione è caratterizzata da una asimmetria destra (i valori oltre la media sono più frequenti), - è negativo quando la distribuzione ha una asimmetria sinistra (i valori oltre la media sono meno frequenti). Ma il valore assoluto di questo indice è fortemente dipendente dalla scala utilizzata (una distribuzione di lunghezze misurata in millimetri ha un valore di asimmetria maggiore della stessa distribuzione misurata in metri).
Per rendere questa misura adimensionale, cioè indipendente
dal tipo di scala e uguale per tutte le distribuzioni che hanno la stessa
forma, occorre dividere il momento di terzo ordine (m3) per
Da questo concetto sono derivati i due indici più diffusi, tra loro collegati da una relazione matematica semplice: - l’indice b1 di Pearson
- l’indice g1 di Fisher
Quando calcolati su una distribuzione sperimentale, essi sono indicati rispettivamente con b1 e g1 Di conseguenza, il valore della skewness di una distribuzione sperimentale è
dove
e
Nel calcolo del momento di secondo ordine, cioè della varianza, anche
il testo di Snedecor-Cochran indica
Riprendendo la stessa distribuzione di frequenza gia utilizzata in precendenza per la verifica della normalità mediante il test c2,
i calcoli possono essere semplificati, rispetto alla formula presentata con i momenti, indicando le classi con valori prestabiliti.
Poiché l’indice è adimensionale e quindi le classi possono avere valori convenzionali, diversi da quelli effettivamente rilevati, è conveniente modificare la scala delle classi: si indica con 0 (zero) la classe centrale (più frequente), con interi negativi quelle inferiori e con interi positivi quelle superiori (vedi quarta colonna, indicata con U, dove le classi sono state fatte variare da –4 a 8, ma potevano ugualemente variare da –6 a 6 o qualsiasi altra serie di valori convenzionali). La metodologia abbreviata, utile per i calcoli manuali, richiede che questo valore sia elevato al quadrato (vedi colonna U2) e al cubo (vedi colonna U3). L’elevamento alla quarta (U4) è richiesto nel test successivo, utile per la verifica della significatività del grado di curtosi.
Dopo aver ottenuto le somme
si ricavano h1, h2 e h3 con
Infine da essi m2 con
e m3 con
I momenti di secondo ordine (m2) e di terzo ordine (m3) intorno alla media, per i dati sperimentali raccolti, sono m2 = 4,4224 e m3 = 4,376977.
Infine con
si ottiene l’indice di skewness
In campioni grandi (in alcuni testi n > 150; in altri, più rigorosi, n ³ 500) estratti casualmente da una popolazione normale, - questi indici sono distribuiti in modo approssimativamente normale, - con media m = 0 - e deviazione standard s =
TAVOLA DEI VALORI CRITICI DELL’INDICE DI SKEWNESS (in valore assoluto)
Nell’esempio (n = 500), la deviazione standard (s) dell’indice di skewness è s =
E’ quindi possibile valutare, - con un test bilaterale se l’asimmetria è diversa da 0 H0: g1 = 0 contro H1: g1 ¹ 0
- oppure con un test unilaterale se esiste asimmetria destra H0: g1 £ 0 contro H1: g1 > 0 o se essa è sinistra H0: g1 ³ 0 contro H1: g1 < 0
Nel caso di campioni
grandi (in alcuni testi n > 150; in altri, più
rigorosi, n ³ 500), utilizzando l’indice di skewness
calcolato ( ricavando Z con la formula
derivata dalla formula generale
Con i dati dell’esempio
risulta un valore di Z (4,29) molto alto, al quale nella tavola della distribuzione normale corrisponde una probabilità a < 0.0001 sia per un test a una coda sia per un test a due code. In conclusione, si può affermare che nella distribuzione osservata è presente una asimmetria destra altamente significativa.
Nel caso di campioni
piccoli (n £ 150), occorre utilizzare una distribuzione
specifica che fornisce una approssimazione più accurata. E’ possibile ricorrere
alla tabella dei valori critici riportata in precedenza, tratta dal testo di
Snedecor e Cochran e valida sia per Alla probabilità a prefissata sono
significativi gli indici
Il test per la kurtosis (raramente chiamata anche peakedness o tailed-ness) di una popolazione di dati è fondato sul valore medio della quantità
diviso per In una popolazione distribuita in modo normale risulta uguale a 3. Gli indici di curtosi b2 di Pearson e g2 di Fisher sono ricavati da
dove
Per stimare b2 da una distribuzione di frequenza (utilizzando la stessa impiegata per l’asimmetria) dopo aver calcolato oltre ai parametri precedenti anche
e
con
si ricava
m4 = 60,2948. Infine si ottengono b2
e g2
In campioni grandi (in alcuni testi n > 1.000; in altri, più rigorosi, n ³ 2.000), il valore g2 è distribuito in modo approssimativamente normale con m = 0 e s = Nell’esempio (n = 500), la deviazione standard (s) dell’indice di kurtosis è (molto) approssimativamente s =
E’ quindi possibile valutare, - con un test bilaterale se l’indice di curtosi g2 è diversa da 0 H0: g2 = 0 contro H1: g2 ¹ 0
- oppure con un test unilaterale se la curva è platicurtica H0: g2 £ 0 contro H1: g2 > 0 o se essa è leptocurtica H0: g2 ³ 0 contro H1: g2 < 0
Nel caso di campioni grandi, utilizzando l’indice di curtosi calcolato (b2–3 oppure g2), si valuta la sua significatività ricavando Z con la formula
derivata dalla formula generale
VALORI CRITICI SUPERIORI E INFERIORI DI b2 PER IL TEST DI KURTOSIS ALLE PROBABILITA’ a = 0.05 E a = 0.01
Con i dati dell’esempio, anche se in realtà il campione è troppo piccolo per questo test,
risulta un valore di Z (0,38) piccolo. Ad esso corrisponde una probabilità - a = 0,3620 in un test bilaterale, - a = 0,1810 in un test unilaterale. Sono probabilità comunque molto alte, che non solo non rifiutano l’ipotesi nulla ma permettono di affermare cha la distribuzione è molto simile alla normale, per quanto riguarda la curtosi.
Per campioni piccoli, (n < 2.000) il testo di Snedecor-Cochran riporta i valori critici di b2 alla probabilità a = 0.05 e a = 0.01 stimati da Pearson. Dalla loro lettura, è semplice osservare che non sono distribuiti in modo simmetrico intorno a 3. Per n = 500, alla probabilità a = 0.05 il limite superiore è +0,37 rispetto al valore centrale, mentre il limite inferiore è –0,33. I due scarti diventano molto simili, alla seconda cifra decimale, solo quando n = 2.000. Alla probabilità a prescelta, sono significativi tutti i valori di b2 esterni a questo intervallo. Per la significatività di g2 è sufficiente sottrarre 3 ai valori della tabella.
Durante i primi decenni
del Novecento, sono state utilizzate le quantità g1 e g2
per stimare la distribuzione di dati in popolazioni non normali, caratterizzate
dai parametri g1 e g2. E’ stato dimostrato, come afferma il Teorema del Limite Centrale, che
in una distribuzione di medie campionarie (
Un altro aspetto
interessante è che la curtosi(g2) aumenta la varianza di un campione( attraverso la relazione
dove n sono i gdl del campione.
Se in una
popolazione con varianza
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||