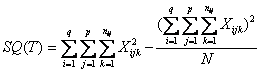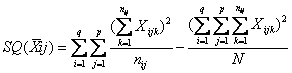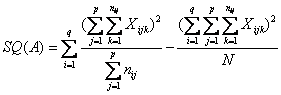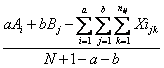|
analisi FATTORIALE E disegni complessi CON FATTORI INCROCIATI
12.4. ANALISI DELLA VARIANZA A DUE FATTORI CON REPLICHE INEGUALI
Le procedure illustrate nei paragrafi precedenti per l’analisi della varianza nel caso di due fattori con repliche richiedono che il loro numero (r) entro ogni cella sia sempre uguale. La potenza del test è massima e l’interpretazione dei risultati è più semplice; ma nella pratica della ricerca non sempre è possibile rispettare uno schema così rigido. Quando il numero di dati entro ogni casella non è costante, in un’analisi a due fattori è ancora possibile ricorrere a formule semplici, utilizzabili per calcoli manuali, se il numero di repliche entro ogni casella è proporzionale. Come nella tabella
sottostante (con 4 livelli per il fattore A e 3 livelli per il fattore B),
nella quale i dati riportati (
si può parlare di numero proporzionale di repliche quando
dove -
-
-
-
Nell’esempio riportato, si può parlare di numero proporzionale di repliche poiché per tutte le celle è vera la relazione precedente; ad esempio, -
in
quella posta all’incrocio tra
-
in
quella posta all’incrocio tra
Utilizzando le formule abbreviate, in uno schema con repliche proporzionali, in cui - ogni riga i abbia q livelli - ogni colonna j abbia p livelli - ogni k cella abbia un numero variabile di repliche nij, si stima - la devianza totale SQ(T) con gdl = N-1 (nell’esempio, 72-1 = 71)
-
la devianza tra le celle
- la devianza del fattore A SQ(A) con gdl = q-1 (nell’esempio, 4-1 = 3)
- la devianza del fattore B SQ(B) con gdl = p-1 (esempio, 3-1 = 2)
- la devianza d’interazione SQ(AB) con gdl = (q×p-1) – (q-1) – (p-1) = (q-1)×(p-1) (nell’esempio, 11 – 3 – 2 = 3 × 2 = 6) SQ(AB) =
- la devianza d’errore SQ(e) con gdl (N – 1) - (q × p –1); (nell’esempio, 71 – 11 = 60) SQ(e) = SQ(T) -
Se le frequenze di osservazioni entro ogni cella non è proporzionale (l’uguaglianza del numero di repliche ne rappresenta solo un caso particolare), le formule sono più complesse e la loro applicazione diventa possibile solo con programmi informatici. E’ quindi utile cercare di condurre i casi che se ne allontanano di poco allo schema del modello proporzionale, - eliminando casualmente l’osservazione in eccesso entro le celle interessate, - inserendo il dato mancante.
Come stimare un dato mancante nei casi più semplici è come correggere le varianze è già stato presentato nel capitolo precedente. In questo caso, G. P. Shearer nel 1973 (vedi l’articolo Missing data in quantitative designs.pubblicato su Journal of the Royal Statistical Society, Ser. C Appl. Statist. 22: 135-140), ripresa da Jerrold H. Zar nel testo Biostatistical Analysis del 1999 (fourth edition, Prentice Hall, New Jersey), propone di inserire
il valore
dove -
-
-
-
Se il numero di dati mancanti è superiore a 1, ma secondo vari autori non devono superare il 10% del numero totale di osservazioni, si deve usare un metodo iterativo, già illustrato nei suoi concetti nel capitolo precedente. Nel caso di disegni sperimentali non proporzionali, la procedura è più complessa. In tutti questi casi, la soluzione reale è demandata ai programmi informatici. E’ importante ricordare che - eliminare uno o più dati riduce di altrettanto i gdl totali e della devianza d’errore, senza incidere sulle altre; - aggiungere uno o più dati non modifica i gdl totali e della devianza d’errore.
| |||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |