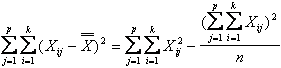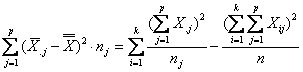ANALISI DELLA VARIANZA a piu’ criteri di classificazione
11.1. ANALISI DELLA VARIANZA A DUE CRITERI DI CLASSIFICAZIONE O A BLOCCHI RANDOMIZZATI, CON UNA SOLA OSSERVAZIONE PER CASELLA
L'analisi della varianza ad un criterio di classificazione o completamente randomizzata è lo schema più semplice di confronto simultaneo tra più medie. Nella pratica sperimentale, spesso rappresenta un’impostazione troppo elementare; infatti, in modo implicito, assume che tutta la variabilità presente nei diversi gruppi a confronto sia determinata dai differenti livelli o dalle varie modalità del solo fattore in osservazione. Sovente è utile, quando non necessario, prendere in considerazione almeno due fattori di variabilità, - sia per analizzare gli effetti di due o più cause contemporaneamente, - sia per ridurre la varianza d'errore isolando gli effetti dovuti ad altre cause note.
Nell’analisi ad un criterio di classificazione, si è ricorsi all’esempio di differenti livelli d’inquinamento dell’aria in aree diverse della stessa città. E’ ovvio che, tra gli altri fattori, anche l’ora della rilevazione può determinare differenze sensibili: durante la giornata, il traffico, il riscaldamento domestico e l’attività di molte industrie possono variare significativamente il livello d’inquinamento dell’aria nella stessa zona. Diventa importante effettuare esperimenti in cui, oltre alla località, si considera anche l’ora del campionamento. Nello stesso modo, quando si confronta l’effetto di farmaci o di tossici sulla crescita di cavie, può essere importante la loro classe d’età: cavie giovani, adulte od anziane possono dare risposte sensibilmente diverse, alla somministrazione della stessa sostanza, determinando una forte variabilità nei dati sperimentali. Questa doppia classificazione di ogni misura può avere una duplice finalità: - analizzare separatamente quale sia il contributo del fattore principale e quale quello del secondo fattore; - eliminare l’effetto del secondo fattore sulla varianza d’errore, quando l’interesse fosse indirizzato solo verso il primo ed il secondo fosse considerato esclusivamente come un elemento di forte perturbazione. In questo caso, il metodo permette di ridurre sensibilmente la varianza d’errore e quindi di aumentare la probabilità di trovare differenze significative tra le medie del fattore ritenuto più importante. Con il linguaggio mutato dall’Agraria, il settore di ricerca di Fisher quando impostò l’analisi della varianza, le diverse modalità del primo fattore, di solito quello ritenuto più importante, sono chiamate trattamenti; le diverse modalità del secondo fattore sono chiamate blocchi. L’analisi della varianza a due criteri di classificazione, è chiamata anche analisi a blocchi randomizzati. In particolare negli esperimenti di laboratorio, con l’analisi completamente randomizzata si richiedeva che gli individui, preventivamente riuniti in un gruppo unico, fossero distribuiti a caso tra i vari trattamenti. Nell’analisi a blocchi randomizzati si richiede che gli individui siano dapprima suddivisi in gruppi omogenei, detti blocchi, per il secondo fattore; successivamente gli individui di ogni blocco devono essere attribuiti in modo casuale (random) ai trattamenti (di norma, il metodo richiede l’estrazione di numeri casuali, dopo aver numerato separatamente gli individui dei differenti blocchi). Per esempio, analizzando contemporaneamente l’effetto di tossici su cavie d’età diversa, si richiede dapprima una loro suddivisione per classi d’età, formando gruppi composti esclusivamente da individui giovani, da individui adulti oppure anziani; successivamente, separatamente ed indipendentemente per ogni classe d’età, si devono attribuire casualmente gli individui ai trattamenti.
E’ ovvio che, se i trattamenti sono n, ogni blocco deve comprendere almeno n individui. Quelli eccedenti, non estratti nell’attribuzione casuale per blocco, sono esclusi dall’esperimento.
Nell’analisi della varianza a due criteri di classificazione, è utile alla comprensione del metodo statistico riportare le osservazioni in una tabella a doppia entrata. Per convenzione ampiamente diffusa, quasi sempre i trattamenti sono riportati in colonna ed i blocchi nelle righe:
Per indicare valori e medie, si ricorre ad una simbologia a due indici, analoga a quella illustrata per l’analisi della varianza ad un criterio di classificazione, con la sola differenza di dover considerare anche le medie di riga o dei blocchi. Nell’analisi della varianza a due criteri, si possono avere due situazioni differenti che richiedono metodi parzialmente diversi. In ogni casella data dall’intersezione tra un trattamento ed un blocco si può avere una sola misura oppure almeno due misure. Quando si hanno due o più repliche per ogni casella, è plausibile supporre che queste misure siano tra loro più simili: l’errore o residuo sarà misurato mediante esse, sulla base dello scarto di ogni replica dalla media di casella. Tale approccio verrà analizzato nei prossimi paragrafi, presentando l’analisi dell’interazione con gli esperimenti fattoriali. Il caso più semplice, analizzato in questo paragrafo, è quello di una sola osservazione ad ogni intersezione tra riga (blocco) e colonna (trattamento). Come presentato nel caso di un solo criterio, l’analisi della varianza utilizza il modello lineare o additivo. Con due criteri di classificazione ed una sola osservazione, ogni dato può essere rappresentato con
dove : - - - bk = m k - m - - sia tutti gli altri fattori non considerati, gli effetti di campionamento e l’eventuale errore strumentale, già presentati nell’errore dell’analisi ad un criterio e simboleggiati complessivamente da epk, - sia l’interazione tra i due fattori che, con una sola osservazione per casella, non può essere stimata.
In riferimento ai dati campionari raccolti con un esperimento di laboratorio oppure in campagna, ogni singolo valore Xpk è stimato come somma di 4 valori Xpk = che dipendono rispettivamente -
dalla
media generale -
dall’effetto
del fattore A, che per ogni trattamento è stimato mediante la differenza -
dall’effetto
del fattore B, che per ogni blocco è stimata dalla differenza - da tutti gli altri fattori non considerati e dall’interazione tra i due fattori A e B, compresi entrambi nella quantità Rpk.
L'analisi della varianza a due criteri di classificazione con una sola osservazione per casella permette di verificare, in modo simultaneo ed indipendente, la significatività delle differenze tra le medie dei trattamenti (fattore A) e tra le medie dei blocchi (fattore B). Per esempio, indicando con a, b, c, d quattro trattamenti e con 1, 2, 3, 4, 5 cinque blocchi, tale concetto viene espresso mediante - una prima ipotesi nulla H0 di uguaglianza delle medie dei trattamenti o del fattore A, per il fattore A H0: ma = mb = mc = md con ipotesi alternativa H1 : non tutte le m dei 4 trattamenti sono tra loro uguali
- una seconda ipotesi nulla di uguaglianza delle medie dei blocchi o del fattore B per il fattore B H0: m1 = m2 = m3 = m4 = m5 con ipotesi alternativa H1 : non tutte le m dei 5 blocchi sono tra loro uguali.
Per questi confronti tra medie, la metodologia richiede il calcolo delle seguenti quantità: 1 - la devianza totale, con gdl p×k - 1 = n - 1; 2 - la devianza tra trattamenti, con gdl p - 1, e la rispettiva varianza; 3 - la devianza tra blocchi, con gdl k - 1, e la rispettiva varianza; 4 - la devianza d'errore, con gdl (p - 1)×(k - 1) = (n - 1) - [(p - 1) + (k - 1)] e la sua varianza.
Le 4 devianze e i relativi gradi di libertà godono della proprietà additiva:
Nella presentazione dei risultati, queste quantità vengono abitualmente riportate per convenzione in una tabella come la seguente:
(nei programmi informatici, sovente la devianza totale ed i suoi gdl sono riportati come ultimi, per evidenziare graficamente che rappresentano la somma delle altre tre quantità).
La devianza totale misura la variazione totale tra le osservazioni; con la formula euristica e quella abbreviata è calcolata come
La devianza tra trattamenti misura la variazione tra le medie dei trattamenti; con formula euristica e quella abbreviata è data da
La devianza tra blocchi misura la variazione tra le medie dei blocchi; la formula euristica e quella abbreviata sono
La devianza d'errore, detta anche residuo, misura la variazione che rimane di ogni osservazione dopo aver tolto gli effetti dei fattori già considerati. Il procedimento diretto, corrispondente alla formula euristica, è lungo; per una presentazione semplice e chiara verrà illustrato con i dati dell’esempio. Abitualmente, con formula equivalente a quella abbreviata, il calcolo viene effettuato ricorrendo alla proprietà additiva - delle devianze Devianzaerrore = Devianza totale - (Devianza tra trattamenti + Devianza tra blocchi) - e dei gradi di libertà relativi gdl Devianzaerrore = gdl Devianza totale - (gdl Devianza tra trattamenti + gdl Devianza tra blocchi)
Successivamente, si ottengono - la varianza tra trattamenti, - la varianza tra blocchi e - la varianza d'errore o residuo dividendo le devianze omonime per i rispettivi gdl.
Il test F consiste nel confrontare, mediante il rapporto, sia la varianza tra trattamenti sia quella tra blocchi separatamente con la varianza d'errore.
A) - Per la significatività delle differenze tra le medie dei trattamenti, si calcola il valore di F
e si confronta il risultato calcolato con il valore tabulato alla probabilità a prefissata per i gradi di libertà relativi. Si rifiuta l’ipotesi nulla relativa al fattore A, se il valore calcolato è maggiore di quello riportato nella tabella.
B) - Per la significatività delle differenze tra le medie dei blocchi si calcola un secondo valore di F
e si confronta il risultato con il valore tabulato per i suoi gdl con le stesse modalità. Si rifiuta l’ipotesi nulla relativa al fattore B, se il valore calcolato è superiore a quello riportato nella tabella. Le due analisi sono totalmente indipendenti.
ESEMPIO. Si vuole verificare se esiste una differenza significativa nella quantità di piombo in sospensione nell'aria di 5 zone di una città (A, B, C, D, E).
Poiché si suppone che esista una forte variabilità determinata dall’ora di campionamento, è stata fatta una rilevazione simultanea in ogni zona, con ripetizioni a distanza di 6 ore (alle ore 6, 12, 18 e 24), per un totale di 4 campioni per zona. Esiste una differenza significativa nella presenza media di polveri di piombo in sospensione nell’aria delle 5 zone? Le differenze tra le ore sono significative?
Risposta. Le ipotesi sono relative - sia alle medie dei trattamenti o zone, con ipotesi nulla H0: mA = mB = mC = mD = mD contro l’ipotesi alternativa H1: non tutte le m delle zone sono uguali
- sia alle medie dei blocchi o ore, con ipotesi nulla H0: mI = mII = mIII = mIV contro l’ipotesi alternativa H1: non tutte le m delle ore sono uguali
Dapprima si devono calcolare i totali di colonna, di riga, il totale generale e le medie relative,
utili ai calcoli successivi per le devianze.
Da essi si stimano:
1- la devianza totale, con 19 gdl, ottenuta come scarto al quadrato di ogni valore dalla media generale
oppure con la formula abbreviata
2 - la devianza tra trattamenti o tra zone, con 4 gdl, ottenuta come scarto quadratico di ognuna delle 5 medie di colonna dalla media generale, moltiplicato per il numero di dati della colonna
oppure con la formula abbreviata
3 - la devianza tra blocchi o tra ore, con 3 gdl, ottenuta come scarto quadratico di ognuna delle 4 medie di riga dalla media generale, moltiplicato per il numero di dati su cui è calcolata la media
oppure con la formula abbreviata
(La quantità
4 - la devianza d'errore e i suoi gdl possono essere calcolati in modo rapido per differenza
devianza d'errore = 683,0 - 128,5 - 525,8 = 28,7 gdl della devianza d'errore = 19 - 4 - 3 = 12
Per una presentazione sintetica dei dati raccolti, per una rapida verifica dei calcoli e per la successiva stima delle tre varianze necessarie ai due test F, con gli 8 valori stimati (4 devianze e relativi gdl) è utile costruire la tabella:
La significatività della differenza tra zone è verificata con
un test F che, con gdl 4 e 12, risulta uguale a 13,44, mentre la significatività delle differenze tra ore è verificata con
un test F che, con gdl 3 e 12, risulta uguale a 73,33. I valori critici corrispondenti -
alla
probabilità a
= 0.05 per -
alla
probabilità a
= 0.01 per Con probabilità a inferiore a 0.01 si rifiuta l’ipotesi nulla, sia per le medie delle zone che per le medie delle ore. La differenza tra ore risulta statisticamente più significativa di quella tra zone.
La devianza d'errore è stata calcolata per differenza, sottraendo alla devianza totale quella tra trattamenti e quella tra blocchi. Per comprenderne più esattamente il significato, è proficuo vedere quanto del valore di ogni osservazione è imputabile agli effetti congiunti della media generale, del fattore A e del fattore B (considerati nelle devianze relative) e quanto ai rimanenti fattori raggruppati nel residuo o devianza d’errore. Con i primi 3
fattori, per ogni valore Xpk osservato è possibile calcolare un
valore
Dopo semplificazione, risulta che può essere stimato mediante
la somma della media di riga e della media di colonna, alla quale viene sottratta la media generale.
Con i dati dell’esercizio, dopo aver calcolato le medie marginali e quella totale, è possibile stimare in ogni casella, all’intersezione tra ogni riga e ogni colonna, quale è il valore atteso qualora agissero solamente i tre effetti considerati. La tabella
sottostante riporta questi valori attesi
Se si utilizzasse questa distribuzione per calcolare le 4 devianze, otterremmo valori identici a quelli dell'esempio precedente per la devianza totale, per quella tra trattamenti e per quella tra blocchi; ma la devianza d'errore o residuo risulterebbe uguale a 0.
La devianza d'errore calcolata precedentemente è Devianza d’errore
= data dalla somma dei quadrati degli scarti tra questi valori stimati e quelli reali o osservati.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||