elementi di statistica descrittivaPer DISTRIBUZIONI UNIVARIATe
1.9. ACCURATEZZA, PRECISIONE E SCELTA DEL NUMERO DI CIFRE SIGNIFICATIVE
Un conteggio di poche unità fornisce una misura precisa: con alta probabilità, la sua ripetizione determina lo stesso valore. Un conteggio ripetuto di un campione grande, formato da varie centinaia o migliaia di unità, difficilmente conduce allo stesso risultato, per la frequenza con la quale si commettono errori. D’altronde tale conteggio non è sostanzialmente modificato, se gli individui risultassero 15.612 oppure 15.623. Quando si utilizza una scala continua, cioè da uno strumento si ricava la misura di una lunghezza o di un peso, quasi sempre la ripetizione conduce a valutazioni differenti. Inoltre, a causa della variabilità biologica ed ambientale, se effettuate su più individui e non determinate con troppa approssimazione, queste misure non conducono mai a risultati identici.
Quando si dispone di misure ripetute, la distribuzione dei valori può essere rappresentata e quantificata con gli indici di statistica descrittiva già presentati. Essi servono per rispondere a due domande: - Quale è il valore reale del fenomeno? - Come descrivere la variabilità del fenomeno o l’errore commesso nella sua misura?
Al momento della raccolta dei dati, occorre quindi tenere presente che i valori devono essere misurati con la precisione utile per fornire una risposta accurata alle due domande precedenti. E’ ovvio che quando la misura è approssimata, come il peso di una persona che sia arrotondato al chilogrammo, è impossibile valutare l’errore di una bilancia, se esso è limitato a uno o al massimo due ettogrammi. Nello stesso modo, ma simmetricamente, è assurdo pretendere misure precise al grammo con una bilancia pesa – persone.
Tale concetto è insito nella convenzione con la quale i dati sono espressi. Se si afferma che un individuo pesa 68 Kg., non si intende dire che è esattamente Kg. 68,000 (cioè 68.000 gr), ma un valore compreso tra Kg. 67,5 e 68,5 o, se si vuole una misura più precisa, tra Kg. 67,50 e 68,49. Sulla base dello stesso principio, se si scrive che quell’individuo è alto 1,71 metri, si intende affermare un valore con approssimazione al centimetro; quindi che egli varia tra mm. 1705 e 1715 (o meglio 1,7149). In un conteggio di alcune migliaia di individui, 15.000 non indica che essi sono esattamente quella cifra, ma un dato compreso tra 14.500 e 15.500 (15.499). Un conteggio di 150 individui indica che essi variano tra 145 e 155 unità. Se si vuole fornire una misura estremamente precisa, come può essere un peso fornito in grammi o un‘altezza in millimetri, si dovrebbe acquistare uno strumento più sofisticato di quello abitualmente in commercio. E’ un’operazione che ha un costo, che richiede maggiore attenzione, e potrebbe rappresentare un dispendio inutile di tempo e risorse. Anche le operazioni statistiche avrebbero poi un appesantimento inutile, quando non dannoso, per calcolare gli indici di tendenza centrale, dispersione, simmetria e curtosi. Da queste osservazioni fondate sulla pratica quotidiana deriva che, al momento della raccolta dei dati, si pone un problema pratico non banale. E’ necessario definire quale è il numero di cifre significative che è utile raccogliere; ricordando che - una approssimazione troppo grande conduce a valori identici e fa perdere una parte importante dell’informazione, - una rilevazione troppo fine aumenta inutilmente i costi e i tempi della ricerca, senza accrescere realmente l’informazione sul fenomeno studiato.
Le soluzione di questo dilemma dipende dall’errore che si accetta di commettere. Esso è legato ai concetti di precisione e di accuratezza di una misura, che nel linguaggio comune sono sinonimi. In realtà, nel linguaggio statistico hanno significati differenti.
L’accuratezza è la vicinanza di un valore misurato al suo valore reale (accuracy is the closeness of a measured value to its true value) e in buona parte dipende dallo strumento. Per esempio, nelle misure ecologiche, il metodo delle trappole per la stima della quantità di individui in una popolazione e quello del C-14 per la produzione di plancton nell’oceano tropicale hanno una accuratezza molto bassa; cioè possono essere molto distanti dal valore reale. Ogni stima, ripetuta nelle stesse condizioni, può dare la metà del valore reale. Uno strumento o un reagente che forniscono una risposta sbagliata spesso sono tarati in modo non corretto e sono definiti inaccurati; i valori ottenuti sono biased. Nel processo di misurazione con uno strumento inaccurato si commette un errore sistematico, chiamato appunto bias. Esso rappresenta un problema importante e ricorrente, in molte tecniche di stima di una quantità. In varie discipline, il progresso è spesso collegato alla ricerca di metodi di misurazione più accurati.
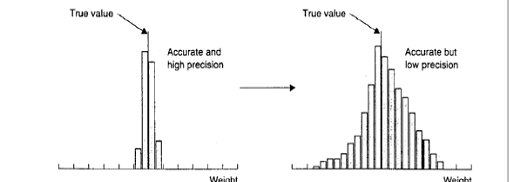
La precisione è la vicinanza di misure ripetute al medesimo valore (precision is the closeness of repeated measuments to the same item). Spesso dipende dalla capacità del tecnico di ripetere la misurazione con le stesse modalità e ha origine dalla sua esperienza o abilità. I concetti di accuracy, precision e bias applicati a una misura di peso sono rappresentati graficamente nella figura successiva tratta dall’ottimo testo, per la stima di popolazioni animali e vegetali, di Charles J. Krebs del 1999 (Ecological methodology, 2nd ed. Menlo Park, CA, Cummings, pp. XII, 620),
Fig. A Fig. B
Fig. C Fig. D
Figura 26. Illustrazione grafica dei concetti di accuratezza (accuracy) e precisione (precision) in misure di peso.
Nella figura A le misure sono accurate, vicine al valore vero (true value), e molto precise (high precision). Nella figura B le misure sono accurate ma poco precise (low precision), cioè differenti tra loro. Nella figura C le misure sono non accurate (biased) ma molto precise (high precision). Nella figura D le misure sono non accurate (biased) e con poco precise (low precision).
Un valore può essere preciso ma inaccurato. Un esempio didattico riportato in alcuni testi, applicato a una misura bidimensionale, è il tiro ad un bersaglio con un’arma, dove la media delle varie prove permette di misurarne l’accuratezza e la loro variabilità la precisione. Se tutti i colpi centrano esattamente il bersaglio o sono molto vicini a esso, con media esattamente sul centro, si ha accuratezza (il fucile è tarato esattamente per le caratteristiche visive di chi spara) e precisione (il tiratore è abile). Se i colpi sono tutti nello stesso posto, ma lontani dal centro del bersaglio, si ha inaccuratezza o misure biased, ma precisione. Il fucile è tarato male, ma il tiratore sa sparare. Se i colpi sono molto dispersi intorno al bersaglio e la loro media coincide con quella del centro, si ha accuratezza ma bassa precisione: il fucile è tarato esattamente, ma il tiratore non sa sparare con precisione (ad esempio, gli trema la mano). Se i colpi formano una rosa molto ampia e la loro media è distante dal centro, si ha inaccuratezza e bassa precisione: lo strumento è biased e l’individuo non sa usarlo correttamente.
Per valutare in modo appropriato questi due fenomeni, soprattutto la dispersione o variabilità dei dati, è importante che le misure raccolte abbiano un numero di cifre significative che sia adeguato. E’ un concetto sfumato, per la soluzione del quale sono state proposte varie metodologie, che si fondano sulla variabilità delle misure campionarie. Il testo di Krebs già citato, sia nella prima edizione del 1989 (pubblicato da Harper Collins) sia nella seconda del 1999 (pubblicata da Benjamin/Cummings), riporta due metodi A - il primo attribuito a Sokal e Rohlf, B - il secondo a Barford. che non forniscono risultati identici. Il secondo è giudicato più conservativo, cioè induce a raccogliere misure con un numero minore di cifre significative.
A - Il metodo di Sokal e Rohlf, proposto sia nel loro testo del 1981 (Biometry, edito da W. H. Freeman, San Francisco) che nella edizione del 1995 (Biometry, editi da W. H. Freeman and Co., New York), non ha alcuna base teorica ma è fondato solo sull’esperienza. Secondo alcuni autori si richiama al buon senso statistico, che ovviamente possono avere solo persone con esperienza. Secondo altri, più critici, è una indicazione a “lume di naso”; ma questi autori non hanno formulato proposte migliori. R. R. Sokal e F. J. Rohlf affermano che, tra la misura minore e quella maggiore, il numero di valori possibili dovrebbe variare tra 30 e 300. Per ottenere questo risultato, è sufficiente che il campo di variazione (range) delle misure da effettuare sia diviso prima per 30 e poi per 300. Ad esempio, per misurare l’altezza di un gruppo di giovani, dove è noto che il fenomeno varia approssimativamente da 150 a 200 cm, - dopo aver determinato il range o campo di variazione range = valore massimo – valore minimo 50 = 200 - 150
- si ricavano il livello minimo di misurazione con il rapporto livello minimo di misurazione = range / 30 livello minimo di misurazione = cm. 50 / 30 = cm. 1,67 dove essa risulta uguale a cm. 1,67
- e il livello massimo di misurazione con il rapporto livello massimo di misurazione = range / 300 livello massimo di misurazione = cm. 50 / 300 = cm. 0,167 dove essa risulta uguale a cm. 0,167.
In termini semplici, quasi banali, è possibile affermare che in questa ricerca il livello di misurazione può variare tra un minimo di circa 1,5 cm. e un massimo di circa 2 mm. Poiché è conveniente ottenere circa 50 valori differenti, un numero compreso nell’intervallo tra 30 e 300, il livello di misurazione può essere il cm. Ma sarebbe ugualmente accettabile volere 100 misure differenti, cioè l’approssimazione a cm 0,5. Invece, se la misurazione avesse come unità 2 cm o peggio ancora 5 cm, si otterrebbero rispettivamente solo 25 e 10 possibili valori differenti, un numero troppo basso. All’opposto, misure che rilevino il mm determinerebbero 500 possibili valori, un numero eccessivamente alto.
ESEMPIO. Qual è il numero di cifre significative per effettuare misurazioni di un fenomeno che varia approssimativamente da gr. 3 a 5?
Risposta. Il campo di variazione è range = gr. 5 – gr. 3 = gr. 2 uguale a gr. 2. Il livello minimo di misurazione è livello minimo di misurazione = gr. 2 / 30 = gr 0,0667 uguale a gr.0,067 mentre il livello massimo è livello massimo di misurazione = cm. 2 / 300 = cm. 0,0067 uguale a gr. 0,0067. In altri termini, - con un solo decimale potrei avere solo 20 valori differenti: è un numero troppo basso; - con due decimali 200 valori, cioè un numero compreso tra 30 e 300; - con tre cifre 2000 valori: un numero troppo alto. In conclusione, la misura corretta dovrebbe valutare il centesimo di grammo; se il numero appare eccessivo per la precisione dello strumento è possibile accettare una misura approssimata a due centesimi (corrispondente a 100 possibili valori differenti) o al massimo a 5 centesimi di grammo (corrispondenti a 40 valori).
B - Il metodo proposto da N. C. Barford nel suo testo del 1985 (Experimental Measurements: Precision, Error and Truth. John Wiley & Sons, New York) è fondato sulla stima dell’errore standard (che misura la dispersione delle medie di n dati). Poiché l’accuratezza relativa dell’errore standard (relative accuracy of standard error) può essere determinata, in modo approssimato, sulla sola base del numero di dati (n) che si vogliono raccogliere
Accuratezza
relativa di es
una volta che sia stata effettuata una misurazione pilota dell’errore standard è possibile stimare l’intervallo di variazione dell’errore probabile dell’errore standard (range of probable error of the standard error) attraverso la relazione
Errore probabile dell’errore standard = (es) · (accuratezza relativa di es)
Da esso si ricava il campo di variazione probabile dell’errore standard e si deduce logicamente il numero di cifre significative.
Riprendendo l’esempio di Krebs, se - si intendono determinare 100 misure (n = 100), - e, con uno studio pilota, sono state stimate sia la media del
campione ( - sia la sua deviazione standard (s = 12,26) dopo aver ricavato l’errore standard con
e la sua accuratezza relativa con accuratezza
relativa di es =
si perviene dapprima alla stima dell’errore probabile di es mediante la relazione errore probabile di es = (es) · (accuratezza relativa di es) errore probabile di
es =
e infine si ottiene il campo probabile di variazione dell’errore standard mediante campo probabile di
variazione dell’errore standard = (es) campo probabile di
variazione dell’errore standard = 1,226
dalla quale si ricava che esso può variare tra 1,3498 (1,226 + 0,1238) e 1.1022 (1,226 – 0,1238). In altri termini esso ha un range range = 1,3498 – 1,1022 = 0,2476 di circa 0,25 mm. Per cogliere una differenza tra i due limiti (circa 1,3 mm e circa 1,1 mm) le misure devono avere la precisione di almeno una cifra decimale, cioè 0,1 mm.
Con questa impostazione, la scelta del numero di cifre significative dipende - dal numero di dati che si intendono raccogliere, - oltre che dalla naturale variabilità del fenomeno (s).
L’errore standard e la sua accuratezza diminuiscono in valore all’aumentare del numero di misure (n) che si vogliono effettuare. Di conseguenza, - il numero di cifre significative diminuisce se n diminuisce: ci si accontenta di una misura meno precisa e quindi anche il numero di cifre significative può essere minore, - il numero di cifre significative cresce all’aumentare di n. Per esempio, con la stessa deviazione standard (s) e solo 10 misure (n = 10), l’errore standard probabile è ± 0,433 e quindi il campo di variazione dell’errore standard è tra 0,8 mm e 1,7 mm. Misure rilevate con una cifra decimale (mm 0,1) sono ampiamente sufficienti per cogliere queste differenze.
| |
| Manuale di Statistica per la Ricerca e la Professione © Lamberto Soliani - Dipartimento di Scienze Ambientali, Università di Parma (apr 05 ed) ebook version by SixSigmaIn Team - © 2007 |